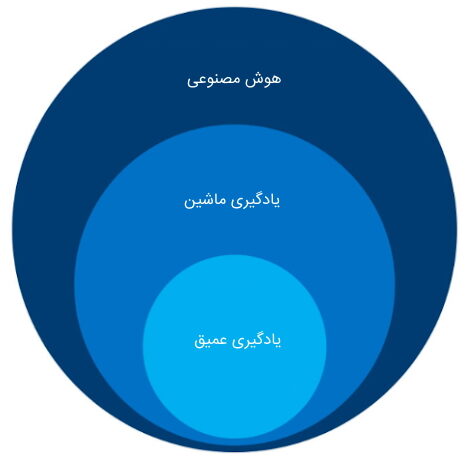
هوش مصنوعی شامل مجموعهای از روشها است که کامپیوتر را قادر میسازد به منظور تصمیمگیری درباره مسائل مختلف، عملکردی هوشمندانه و انسانگونه داشته باشند. به عبارتی، میتوان با هوش مصنوعی دادهها را برای ماشین تفسیر کرد تا آنها را یاد بگیرد و از دانش کسب شده در انجام کارهایی استفاده کند که نیاز به توانمندی هوش انسان دارد. در این راستا، میتوان از روشهای یادگیری ماشین و یادگیری عمیق استفاده کرد تا سیستمهای هوشمندی را به منظور انجام فعالیتهای مختلف آموزش داد. با این حال تفاوت مهمی بین روشهای یادگیری ماشین با روشهای یادگیری عمیق وجود دارد که در ادامه به آن پرداخته میشود.
در علم یادگیری ماشین (Machine Learning)، به موضوع طراحی ماشینهایی پرداخته میشود که با استفاده از مثالهای داده شده به آنها و تجربیات خودشان، بیاموزند. در واقع، در این علم تلاش میشود تا با بهرهگیری از الگوریتمها، یک ماشین به شکلی طراحی شود که بدون آنکه صراحتا برنامهریزی و تک تک اقدامات به آن دیکته شود بتواند بیاموزد و عمل کند. در یادگیری ماشین، به جای برنامهنویسی همه چیز، دادهها به یک الگوریتم عمومی داده میشوند و این الگوریتم است که براساس دادههایی که به آن داده شده منطق خود را میسازد. یادگیری ماشین روشهای گوناگونی دارد که از آن جمله میتوان به یادگیری نظارت شده، نظارت نشده و یادگیری تقویتی اشاره کرد. الگوریتمهای مورد استفاده در یادگیری ماشین جزو این سه دسته هستند.
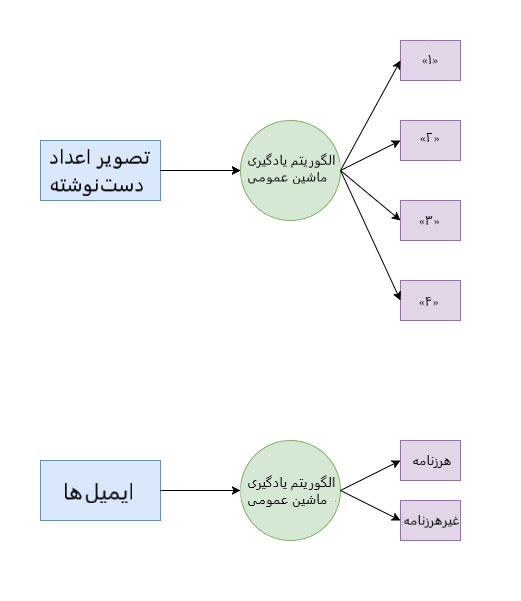
الگوریتم دستهبندی مثالی برای مطلب بیان شده است. این الگوریتم میتواند دادهها را در گروههای (دستههای) مختلف قرار دهد. الگوریتم دستهبندی که برای بازشناسی الفبای دستخط استفاده میشود را میتوان برای دستهبندی ایمیلها به هرزنامه و غیر هرزنامه نیز استفاده کرد.
تام میشل (Tom M. Mitchell) در تعریف یادگیری ماشین میگوید: «(یک برنامه یادگیرنده) برنامه رایانهای است که به آن گفته شده تا از تجربه E مطابق با برخی وظایف T، و کارایی عملکرد P برای وظیفه T که توسط P سنجیده میشود، یاد بگیرد که تجربه E را بهبود ببخشد.»
به عنوان مثالی دیگر، میتوان بازی دوز (چکرز) را فرض کرد.
E: تجربه بازی کردن بازی دوز به دفعات زیاد است.
T: وظیفه انجام بازی دوز است.
P: احتمال آنکه برنامه بتواند بازی بعدی را ببرد است.
مثالهایی از یادگیری ماشین
مثالهای متعددی برای یادگیری ماشین وجود دارند. در اینجا چند مثال از مسائل طبقهبندی زده میشود که در آنها هدف دستهبندی اشیا به مجموعهای مشخص از گروهها است.
تشخیص چهره: شناسایی چهره در یک تصویر (یا تشخیص اینکه آیا چهرهای وجود دارد یا خیر).
فیلتر کردن ایمیلها: دستهبندی ایمیلها در دو دسته هرزنامه و غیر هرزنامه.
تشخیص پزشکی: تشخیص اینکه آیا بیمار مبتلا به یک بیماری است یا خیر.
پیشبینی آب و هوا: پیشبینی اینکه برای مثال فردا باران میبارد یا خیر.
نیازهای یادگیری ماشین
یادگیری ماشین زمینه مطالعاتی است که از هوش مصنوعی سر بر آورده. بشر با استفاده از هوش مصنوعی بهدنبال ساخت ماشینهای بهتر و هوشمند است. اما پژوهشگران در ابتدا به جز چند وظیفه ساده، مانند یافتن کوتاهترین مسیر بین نقطه A و B، در برنامهریزی ماشینها برای انجام وظایف پیچیدهتری که بهطور مداوم با چالش همراه هستند ناتوان بودند. بر همین اساس، ادراکی مبنی بر این شکل گرفت که تنها راه ممکن برای تحقق بخشیدن این مهم، طراحی ماشینهایی است که بتوانند از خودشان یاد بگیرند. ماشین در این رویکرد به مثابه کودکی است که از خودش میآموزد. بنابراین، یادگیری ماشین بهعنوان یک توانایی جدید برای رایانهها مطرح شد. امروزه این علم در بخشهای گوناگون فناوری مورد استفاده قرار میگیرد، و بهرهگیری از آن به اندازهای زیاد شده که افراد اغلب از وجودش در ابزارها و لوازم روزمره خود بیخبرند.
یافتن الگوها در دادههای موجود در سیاره زمین، تنها برای مغز انسان امکانپذیر است. اما هنگامی که حجم دادهها بسیار زیاد میشود و زمان لازم برای انجام محاسبات افزایش مییابد، نیاز به یادگیری ماشین به عنوان علمی مطرح میشود که به افراد در کار با دادههای انبوه در حداقل زمان کمک میکند.
با وجود آنکه مباحث مِهداده (کلان داده/big data) و پردازش ابری به دلیل کاربردی که در جنبههای گوناگون زندگی بشر دارند حائز اهمیت شدهاند، اما در حقیقت یادگیری ماشین فناوری است که به دانشمندان داده در تحلیل بخشهای بزرگ داده، خودکارسازی فرآیندها، بازشناسی الگوها و ارزشآفرینی کمک میکند.
روشی که اکنون برای دادهکاوی استفاده میشود برای سالها مطرح بوده، اما موثر واقع نشده زیرا قدرت رقابتی برای اجرای الگوریتمها نداشته. این در حالی است که امروزه اگر بهعنوان مثال یک الگوریتم یادگیری عمیق با دسترسی به دادههای خوب اجرا شود، خروجی دریافت شده منجر به پیشرفتهای چشمگیری در یادگیری ماشین میشود.
انواع یادگیری ماشین
الگوریتمهای یادگیری ماشین بر سه نوع هستند:
یادگیری نظارت شده
یادگیری نظارت نشده
یادگیری تقویتی
یادگیری نظارت شده
اغلب روشهای یادگیری ماشین از یادگیری نظارت شده استفاده میکنند. در یادگیری ماشین نظارت شده، سیستم تلاش میکند تا از نمونههای پیشینی بیاموزد که در اختیار آن قرار گرفته. به عبارت دیگر، در این نوع یادگیری، سیستم تلاش میکند تا الگوها را بر اساس مثالهای داده شده به آن فرا بگیرد.
به بیان ریاضی، هنگامی که متغیر ورودی (X) و متغیر خروجی (Y) موجودند و میتوان بر اساس آنها از یک الگوریتم برای حصول یک تابع نگاشت ورودی به خروجی استفاده کرد در واقع یادگیری نظارت شده است. تابع نگاشت به صورت (Y = f(X نشان داده میشود.
مثال:
برای باز شدن مساله در ادامه توضیحات بیشتری ارائه میشود. همانطور که پیش از این بیان شد، در یادگیری ماشین مجموعه داده (هایی) به الگوریتم داده میشود و ماشین منطق خود را بر اساس آن مجموعه داده (ها) شکل میدهد. این مجموعه داده دارای سطرها و ستونهایی است. سطرها (که از آنها با عنوان رکورد و نمونه داده نیز یاد میشود) نماینده نمونه دادهها هستند. برای مثال اگر مجموعه داده مربوط به بازیهای فوتبال (وضعیت جوی) باشد، یک سطر حاوی اطلاعات یک بازی خاص است. ستونها (که از آنها با عنوان خصیصه، ویژگی، مشخصه نیز یاد میشود) در واقع ویژگیهایی هستند که هر نمونه داده را توصیف میکنند.https://beta.kaprila.com/a/templates_ver2/templates.php?ref=blog.faradars&id=string-1&w=760&h=140&t=string&bg=fffff3&hover=ffffcb&rows=3&cid=1871,391,2560&wr=cat_2_data_mining,cat_data_mining,cat_2_data_mining
در مثالی که پیشتر بیان شد، مواردی مانند وضعیت هوا شامل ابری بودن یا نبودن، آفتابی بودن یا نبودن، وجود یا عدم وجود مه، بارش یا عدم بارش باران و تاریخ بازی از جمله ویژگیهایی هستند که وضعیت یک مسابقه فوتبال را توصیف میکنند. حال اگر در این مجموعه داده به عنوان مثال، ستونی وجود داشته باشد که مشخص کند برای هر نمونه داده در شرایط جوی موجود برای آن نمونه خاص بازی فوتبال انجام شده یا نشده (برچسبها) اصطلاحا میگوییم مجموعه داده برچسبدار است. اگر آموزش الگوریتم از چنین مجموعه دادهای استفاده شود و به آن آموخته شود که بر اساس نمونه دادههایی که وضعیت آنها مشخص است (بازی فوتبال انجام شده یا نشده)، درباره نمونه دادههایی که وضعیت آنها نامشخص است تصمیمگیری کند، اصطلاحا گفته میشود یادگیری ماشین نظارت شده است.
مسائل یادگیری ماشین نظارت شده قابل تقسیم به دو دسته «دستهبندی» و «رگرسیون» هستند.
دستهبندی: یک مساله، هنگامی دستهبندی محسوب میشود که متغیر خروجی یک دسته یا گروه باشد. برای مثالی از این امر میتوان به تعلق یک نمونه به دستههای «سیاه» یا «سفید» و یک ایمیل به دستههای «هرزنامه» یا «غیر هرزنامه» اشاره کرد.
رگرسیون: یک مساله هنگامی رگرسیون است که متغیر خروجی یک مقدار حقیقی مانند «قد» باشد. در واقع در دستهبندی با متغیرهای گسسته و در رگرسیون با متغیرهای پیوسته کار میشود.
یادگیری نظارت نشده
در یادگیری نظارت نشده، الگوریتم باید خود به تنهایی بهدنبال ساختارهای جالب موجود در دادهها باشد. به بیان ریاضی، یادگیری نظارت نشده مربوط به زمانی است که در مجموعه داده فقط متغیرهای ورودی (X) وجود داشته باشند و هیچ متغیر داده خروجی موجود نباشد. به این نوع یادگیری، نظارت نشده گفته میشود زیرا برخلاف یادگیری نظارت شده، هیچ پاسخ صحیح داده شدهای وجود ندارد و ماشین خود باید به دنبال پاسخ باشد.
به بیان دیگر، هنگامی که الگوریتم برای کار کردن از مجموعه دادهای بهره گیرد که فاقد دادههای برچسبدار (متغیرهای خروجی) است، از مکانیزم دیگری برای یادگیری و تصمیمگیری استفاده میکند. به چنین نوع یادگیری، نظارت نشده گفته میشود. یادگیری نظارت نشده قابل تقسیم به مسائل خوشهبندی و انجمنی است.
قوانین انجمنی: یک مساله یادگیری هنگامی قوانین انجمنی محسوب میشود که هدف کشف کردن قواعدی باشد که بخش بزرگی از دادهها را توصیف میکنند. مثلا، «شخصی که کالای الف را خریداری کند، تمایل به خرید کالای ب نیز دارد».
خوشهبندی: یک مساله هنگامی خوشهبندی محسوب میشود که قصد کشف گروههای ذاتی (دادههایی که ذاتا در یک گروه خاص میگنجند) در دادهها وجود داشته باشد. مثلا، گروهبندی مشتریان بر اساس رفتار خرید آنها.
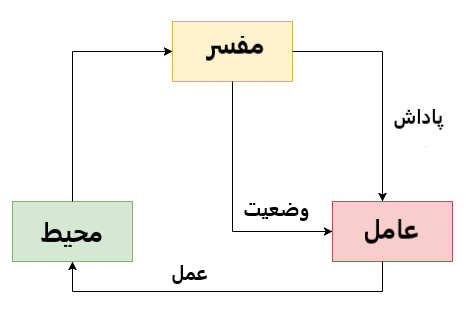
یادگیری تقویتی
یک برنامه رایانهای که با محیط پویا در تعامل است باید به هدف خاصی دستیابد (مانند بازی کردن با یک رقیب یا راندن خودرو). این برنامه بازخوردهایی را با عنوان پاداشها و تنبیهها فراهم و فضای مساله خود را بر همین اساس هدایت میکند. با استفاده از یادگیری تقویتی، ماشین میآموزد که تصمیمات مشخصی را در محیطی که دائم در معرض آزمون و خطا است اتخاذ کند.
مثال:
ریاضیات هوشمندی
نظریه یادگیری ماشین، زمینهای است که در آن آمار و احتمال، علوم رایانه و مباحث الگوریتمی – بر مبنای یادگیری تکرار شونده – کاربرد دارد و میتواند برای ساخت نرمافزارهای کاربردی هوشمند مورد استفادده قرار بگیرد.
چرا نگرانی از ریاضیات؟
دلایل متعددی وجود دارد که آموختن ریاضیات برای یادگیری ماشین را الزامی میکند. برخی از این دلایل در ادامه آورده شدهاند.
انتخاب الگوریتم مناسب برای یک مساله خاص، که شامل در نظر گرفتن صحت، زمان آموزش، پیچیدگی مدل، تعداد پارامترها و تعداد مشخصهها است.
استفاده از موازنه واریانس-بایاس برای شناسایی حالاتی که بیشبرازش با کمبرازش در آنها به وقوع پیوسته است.
انتخاب تنظیمات پارامترها و استراتژیهای اعتبارسنجی.
تخمین دوره تصمیمگیری صحیح و عدم قطعیت.
چه سطحی از ریاضیات مورد نیاز است؟
پرسشی که برای اغلب افراد علاقمند به آموختن علم یادگیری ماشین مطرح است و بارها در مقالات و کنفرانسهای گوناگون این حوزه به آن پاسخ داده شده این است که چه میزان تسلط بر ریاضیات برای درک این علم مورد نیاز محسوب میشود. پاسخ این پرسش چند بُعدی و وابسته به سطح دانش ریاضی هر فرد و میزان علاقمندی آن شخص به یادگیری است. در ادامه حداقل دانش ریاضی که برای مهندسان یادگیری ماشین و تحلیلگران داده مورد نیاز است آورده شده.
جبر خطی: ماتریسها و عملیات روی آنها، پروجکشن، اتحاد و تجزیه، ماتریسهای متقارن، متعامدسازی.
نظریه آمار و احتمالات: قوانین احتمال و اصل (منطق)، نظریه بیزی، متغیرهای تصادفی، واریانس و امید ریاضی، توزیعهای توام و شرطی، توزیع استاندارد.
حساب: حساب دیفرانسیل و انتگرال، مشتقات جزئی.
الگوریتمها و بهینهسازی پیچیدگیها: درختهای دودویی، هیپ، استک
مغر انسان، به اذعان بسیاری از دانشمندان، پیچیدهترین سیستمی است که تا کنون در کل گیتی مشاهده شده و مورد مطالعه قرار گرفته است. اما این سیستم پیچیده نه ابعادی در حد کهشکشان دارد و نه تعداد اجزای سازندهاش، بیشتر از پردازندههای ابررایانههای امروزی است. پیچیدگی راز آلود این سیستم بی نظیر، به اتصالهای فراوان موجود میان اجزای آن بازمیگردد. این همان چیزی است که مغز ۱۴۰۰ گرمی انسان را از همه سیستمهای دیگر متمایز می کند.
فرایندهای خودآگاه و ناخودآگاهی که در حدود جغرافیایی بدن انسان رخ میدهند، همگی تحت مدیریت مغز هستند. برخی از این فرایندها آنقدر پیچیده هستند، که هیچ رایانه یا ابررایانهای در جهان امکان پردازش و انجام آن را ندارد. با این حال، تحقیقات نشان میدهند که واحدهای سازنده مغز انسان، از نظر سرعت عملکرد، حدود یک میلیون بار کندتر از ترانزیستورهای مورد استفاده در تراشههای سیلیکونی CPU رایانه هستند.
سرعت و قدرت پردازش بسیار بالای مغز انسان، به ارتباطهای بسیار انبوهی باز میگردد که در میان سلولهای سازنده مغز وجود دارد و اساساً، بدون وجود این لینکهای ارتباطی، مغز انسان هم به یک سیستم معمولی کاهش مییافت و قطعاً امکانات فعلی را نداشت.
گذشته از همه اینها، عملکرد عالی مغز در حل انواع مسائل و کارایی بالای آن، باعث شده است تا شبیه سازی مغز و قابلیتهای آن به مهمترین آرمان معماران سختافزار و نرمافزار تبدیل شود. در واقع اگر روزی فرا برسد (که البته ظاهرا خیلی هم دور نیست) که بتوانیم رایانهای در حد و اندازههای مغز انسان بسازیم، قطعاً یک انقلاب بزرگ در علم، صنعت و البته زندگی انسانها، رخ خواهد داد.
از چند دهه گذشته که رایانهها امکان پیادهسازی الگوریتمهای محاسباتی را فراهم ساختهاند، در راستای شبیهسازی رفتار محاسباتی مغز انسان، کارهای پژوهشی بسیاری از سوی متخصصین علوم رایانه، مهندسین و همچنین ریاضیدانها شروع شده است، که نتایج کار آنها، در شاخهای از علم هوش مصنوعی و در زیرشاخه هوش محاسباتی تحت عنوان موضوع «شبکههای عصبی مصنوعی» یا Artificial Neural Networks (به اختصار: ANNs) طبقهبندی شده است. در مبحث شبکههای عصبی مصنوعی، مدلهای ریاضی و نرمافزاری متعددی با الهام گرفتن از مغز انسان پیشنهاد شدهاند، که برای حل گستره وسیعی از مسائل علمی، مهندسی و کاربردی، در حوزه های مختلف کاربرد دارند.
کاربردهای شبکههای عصبی مصنوعی
امروز به قدری استفاده از سیستمهای هوشمند و به ویژه شبکه عصبی مصنوعی گسترده شده است که میتوان این ابزارها را در ردیف عملیات پایه ریاضی و به عنوان ابزارهای عمومی و مشترک، طبقهبندی کرد. چرا که کمتر رشته دانشگاهی است که نیازی به تحلیل، تصمیمگیری، تخمین، پیشبینی، طراحی و ساخت داشته باشد و در آن از موضوع شبکههای عصبی استفاده نشده باشد. فهرستی که در ادامه آمده است، یک فهرست نه چندان کامل است. اما همین فهرست مختصر نیز گستردگی کاربردهای شبکههای عصبی مصنوعی را تا حدود زیادی به تصویر میکشد.
زمینه کلی
کاربرد
علوم کامپیوتر
طبقهبندی اسناد و اطلاعات در شبکههای کامپیوتری و اینترنتتوسعه نرمافزارهای نظارتی و نرمافزارهای آنتیویروس
علوم فنی و مهندسی
مهندسی معکوس و مدلسازی سیستمهاپیشبینی مصرف بار الکتریکیعیبیابی سیستمهای صنعتی و فنیطراحی انواع سیستمهای کنترلطراحی و بهینهسازی سیستمهای فنی و مهندسیتصمیمگیری بهینه در پروژههای مهندسی
علوم پایه و نجوم
پیشبینی نتایج آزمایشهاارزیابی و تخمین صحت فرضیهها و نظریههامدلسازی پدیدههای فیزیکی پیچیده
علوم پزشکی
مدلسازی فرایندهای زیست-پزشکیتشخیص بیماریها با توجه به نتایج آزمایش پزشکی و تصویربرداریپیشبینی نتایج درمان و عمل جراحیپیادهسازی ادوات و الگوهای درمانی اختصاصی بیمار
علوم تجربی و زیستی
مدلسازی و پیشبینی پدیدههای زیستی و محیطیپیشبینی سریهای زمانی با کاربرد در علوم زیست-محیطیطبقهبندی یافتههای ناشی از مشاهدات تجربیشناسایی الگوهای مخفی و تکرار شونده در طبیعت
علوم اقتصادی و مالی
پیشبینی قیمت سهام و شاخص بورسطبقهبندی علائم و نمادهای بورستحلیل و ارزیابی ریسکتخصیص سرمایه و اعتبار
علوم اجتماعی و روانشناسی
طبقهبندی و خوشهبندی افراد و گروههامدلسازی و پیشبینی رفتارهای فردی و اجتماعی
هنر و ادبیات
پیشبینی موفقیت و مقبولیت عمومی آثار هنریاستخراج مولفههای اساسی از متون ادبی و آثار هنریطبقهبندی و کاوش متون ادبی
علوم نظامی
هدفگیری و تعقیب در سلاحهای موشکیپیادهسازی سیستمهای دفاعی و پدافند هوشمندپیشبینی رفتار نیروی مهاجم و دشمنپیادهسازی حملات و سیستمهای دفاعی در جنگ الکترونیک (جنگال)
انواع شبکههای عصبی مصنوعی
انواع مختلفی از مدلهای محاسباتی تحت عنوان کلی شبکههای عصبی مصنوعی معرفی شدهاند که هر یک برای دستهای از کاربردها قابل استفاده هستند و در هر کدام از وجه مشخصی از قابلیتها و خصوصیات مغز انسان الهام گرفته شده است.
در همه این مدلها، یک ساختار ریاضی در نظر گرفته شده است که البته به صورت گرافیکی هم قابل نمایش دادن است و یک سری پارامترها و پیچهای تنظیم دارد. این ساختار کلی، توسط یک الگوریتم یادگیری یا تربیت (Training Algorithm) آن قدر تنظیم و بهینه میشود، که بتواند رفتار مناسبی را از خود نشان دهد.https://beta.kaprila.com/a/templates_ver2/templates.php?ref=blog.faradars&id=string-1&w=760&h=140&t=string&bg=fffff3&hover=ffffcb&rows=3&cid=200,42,33&wr=score_2,cat_2_neural_network,cat_low_neural_network
نگاهی به فرایند یادگیری در مغز انسان نیز نشان میدهد که در واقع ما نیز در مغزمان فرایندی مشابه را تجربه میکنیم و همه مهارتها، دانستهها و خاطرات ما، در اثر تضعیف یا تقویت ارتباط میان سلولهای عصبی مغز شکل میگیرند. این تقویت و تضعیف در زبان ریاضی، خود را به صورت تنظیم یک پارامتر (موسوم به وزن یا Weight) مدلسازی و توصیف میکند.
اما طرز نگاه مدلهای مختلف شبکههای عصبی مصنوعی کاملا متفاوت است و هر یک، تنها بخشی از قابلیتهای یادگیری و تطبیق مغز انسان را هدف قرار داده و تقلید کردهاند. در ادامه به مرور انواع مختلف شبکههای عصبی پرداختهایم که مطالعه آن در ایجاد یک آشنایی اولیه بسیار موثر خواهد بود.
پرسپترون چندلایه یا MLP
یکی از پایهایترین مدلهای عصبی موجود، مدل پرسپترون چند لایه یا Multi-Layer Perceptron (به اختصار MLP) است که عملکرد انتقالی مغز انسان را شبیهسازی میکند. در این نوع شبکه عصبی، بیشتر رفتار شبکهای مغز انسان و انتشار سیگنال در آن مد نظر بوده است و از این رو، گهگاه با نام شبکههای پیشخورد (Feedforward Networks) نیز خوانده میشوند. هر یک از سلولهای عصبی مغز انسان، موسوم به نورون (Neuron)، پس از دریافت ورودی (از یک سلول عصبی یا غیر عصبی دیگر)، پردازشی روی آن انجام میدهند و نتیجه را به یک سلول دیگر (عصبی یا غیر عصبی) انتقال میدهند. این رفتار تا حصول نتیجهای مشخص ادامه دارد، که احتمالاً در نهایت منجر به یک تصمیم، پردازش، تفکر و یا حرکت خواهد شد.
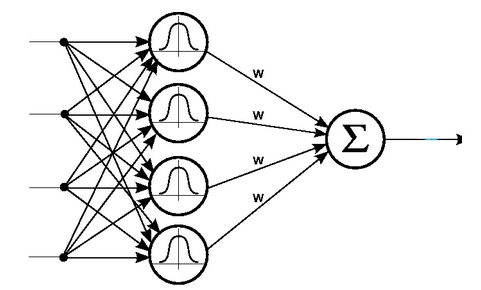
مشابه الگوی شبکههای عصبی MLP، نوع دیگری از شبکههای عصبی وجود دارند که در آنها، واحدهای پردازنده، از نظر پردازشی بر موقعیت خاصی متمرکز هستند. این تمرکز، از طریق توابع شعاعی یا Radial Basis Functions (به اختصار RBF) مدلسازی میشود. از نظر ساختار کلی، شبکههای عصبی RBF تفاوت چندانی با شبکههای MLP ندارند و صرفا نوع پردازشی که نورونها روی ورودهایشان انجام میدهند، متفاوت است. با این حال، شبکههای RBF غالبا دارای فرایند یادگیری و آمادهسازی سریعتری هستند. در واقع، به دلیل تمرکز نورونها بر محدوده عملکردی خاص، کار تنظیم آنها، راحتتر خواهد بود.
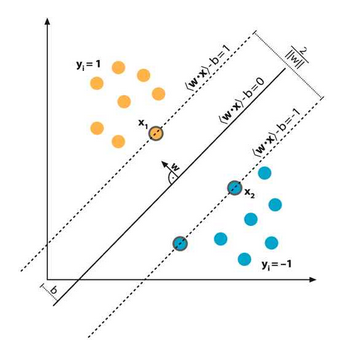
در شبکههای عصبی MLP و RBF، غالبا توجه بر بهبود ساختار شبکه عصبی است، به نحوی که خطای تخمین و میزان اشتباههای شبکه عصبی کمینه شود. اما در نوع خاصی از شبکه عصبی، موسوم به ماشین بردار پشتیبان یا Support Vector Machine (به اختصار SVM)، صرفا بر روی کاهش ریسک عملیاتی مربوط به عدم عملکرد صحیح، تمرکز میشود. ساختار یک شبکه SVM، اشتراکات زیادی با شبکه عصبی MLP دارد و تفاوت اصلی آن عملاً در شیوه یادگیری است.
شبکه عصبی کوهونن (Kohonen) یا نگاشت خودسازمانده و یا Self-Organizing Map (به اختصار SOM) نوع خاصی از شبکه عصبی است که از نظر شیوه عملکرد، ساختار و کاربرد، کاملاً با انواع شبکه عصبی که پیش از این مورد بررسی قرار گرفتند، متفاوت است. ایده اصلی نگاشت خودسازمانده، از تقسیم عملکردی ناحیه قشری مغز، الهام گرفته شده است و کاربرد اصلی آن در حل مسائلی است که به مسائل «یادگیری غیر نظارت شده» معروف هستند. در واقع کارکرد اصلی یک SOM، در پیدا کردن شباهتها و دستههای مشابه در میان انبوهی از دادههایی است که در اختیار آن قرار گرفته است. این وضعیت مشابه کاری است که قشر مغز انسان انجام میدهد و انبوهی از ورودیهای حسی و حرکتی به مغز را در گروههای مشابهی طبقهبندی (یا بهتر است بگوییم خوشهبندی) کرده است.
این نوع خاص شبکه عصبی، تعمیم ایده شبکههای عصبی SOM برای حل مسائل یادگیری نظارت شده است. از طرفی شبکه عصبی LVQ (یا Learning Vector Quantization)، میتواند به این صورت تعبیر شود که گویا شبکه عصبی MLP با یک رویکرد متفاوت، کاری را که باید انجام بدهد یاد میگیرد. اصلیترین کاربرد این نوع شبکه عصبی در حل مسائل طبقهبندی است که گستره وسیعی از کاربردهای سیستمهای هوشمند را پوشش میدهد.
شبکه عصبی هاپفیلد یا Hopfield
این نوع شبکه عصبی، بیشتر دارای ماهیتی شبیه به یک سیستم دینامیکی است که دو یا چند نقطه تعادل پایدار دارد. این سیستم با شروع از هر شرایط اولیه، نهایتا به یکی از نقاط تعادلش همگرا میشود. همگرایی به هر نقطه تعادل، به عنوان تشخیصی است که شبکه عصبی آن را ایجاد کرده است و در واقع میتواند به عنوان یک رویکرد برای حل مسائل طبقهبندی استفاده شود. این سیستم، یکی از قدیمیترین انواع شبکههای عصبی است که دارای ساختار بازگشتی است و در ساختار آن فیدبکهای داخلی وجود دارند.
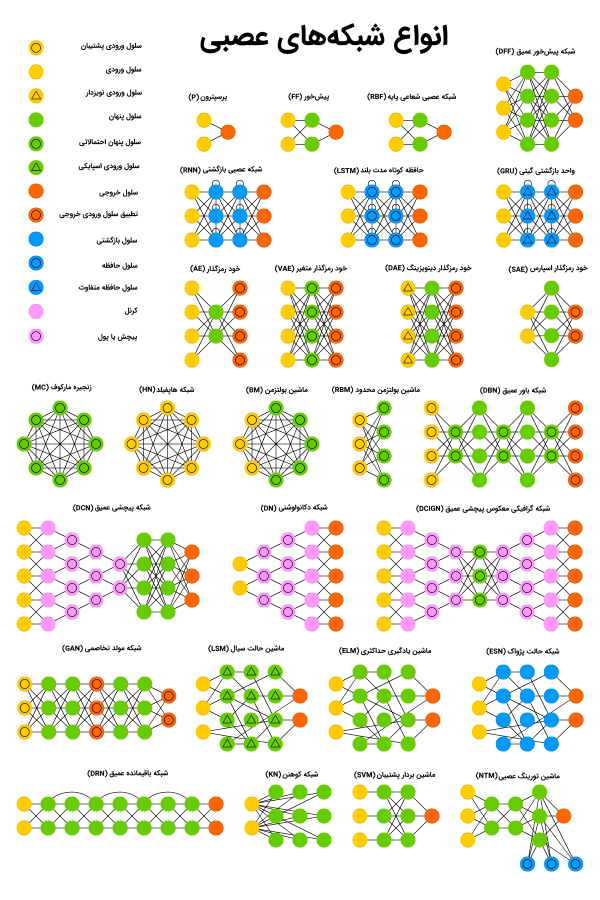
خانواده «شبکههای عصبی مصنوعی» (Artificial Neural Networks) هر روز شاهد حضور اعضای جدیدی است. با توجه به تعدد انواع شبکه های عصبی موجود، در این مطلب، یک راهنمای جامع از انواع شبکه های عصبی مصنوعی ارائه شده است. در این راهنما، توپولوژی انواع شبکه های عصبی مصنوعی روش عملکرد و کاربرد شبکههای عصبی مصنوعی مورد بررسی قرار گرفته است. برای آشنایی با مفهوم شبکههای عصبی مصنوعی و پیادهسازی آن در زبانهای برنامهنویسی گوناگون، مطالعه مطالب زیر پیشنهاد میشود.
در ادامه، ۲۷ مورد از انواع شبکه های عصبی مصنوعی، معرفی شده است. در تصویر زیر، راهنمای جامع انواع شبکههای عصبی ارائه شده است. برای مشاهده این راهنمای جامع در ابعاد بزرگ، کلیک کنید.
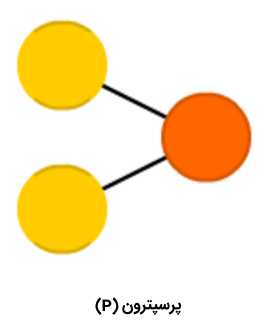
«پرسپترون» (Perceptron | P)، سادهترین و قدیمیترین مدل از نورون محسوب میشود که تاکنون توسط بشر شناخته شده است. پرسپترون، تعدادی ورودی را دریافت، آنها را تجمیع و تابع فعالسازی را روی آنها اعمال میکند و در نهایت، آنها را به لایه خروجی پاس میدهد. در این قسمت، معجزه اصلی شبکههای عصبی مصنوعی به وقوع نمیپیوندد. برای مطالعه بیشتر پیرامون پرسپترون چند لایه، مطالعه مطلب «پرسپترون چند لایه در پایتون — راهنمای کاربردی» پیشنهاد میشود.
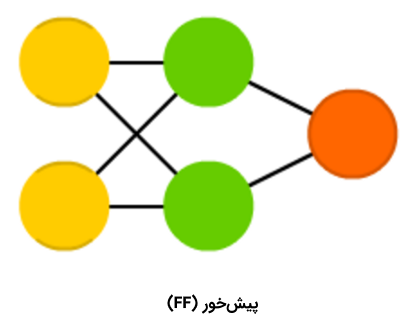
شبکه عصبی پیشخور
«شبکههای عصبی پیشخور» (Feed Forward Neural Networks | FF) نیز از اعضای قدیمی خانواده شبکههای عصبی محسوب میشوند و رویکرد مربوط به آنها از دهه ۵۰ میلادی نشأت میگیرد. عملکرد این الگوریتم، به طور کلی از قواعد زیر پیروی میکند:
همه گرهها کاملا متصل هستند.
فعالسازی از لایه ورودی به خروجی، بدون داشتن حلقه رو به عقب، جریان پیدا میکند.
یک لایه (لایه پنهان) بین ورودی و خروجی وجود دارد.
در اغلب مواقع، این نوع از شبکههای عصبی با استفاده از روش «پسانتشار» (Backpropagation) آموزش داده میشوند.
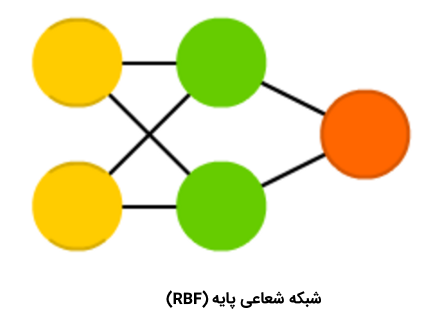
شبکه عصبی شعاعی پایه
«شبکههای عصبی شعاعی پایه» (Radial Basis Networks | RBF) در واقع شبکههای عصبی پیشخوری (FF) هستند که از «تابع شعاعی پایه» (Radial Basis Function)، به جای «تابع لجستیک» (Logistic Function)، به عنوان تابع فعالسازی استفاده میکنند. سوالی که در این وهله مطرح میشود این است که تفاوت شبکه عصبی شعاعی پایه با شبکه عصبی پیشخور چیست؟ تابع لجستیک برخی از مقادیر دلخواه را به یک بازه ۰ تا ۱ نگاشت میکند تا به یک پرسش «بله یا خیر» (پرسش دودویی) پاسخ دهد. این نوع از شبکههای عصبی برای «دستهبندی» (Classification) و «سیستمهای تصمیمگیری» (Decision Making Systems) مناسب هستند، ولی برای مقادیر پیوسته عملکرد بدی دارند.
این در حالی است که توابع شعاعی پایه به این پرسش پاسخ میدهند که «چقدر از هدف دوریم؟» و این امر موجب میشود تا این شبکههای عصبی برای تخمین تابع و کنترل ماشین (برای مثال، به عنوان جایگزینی برای کنترل کننده PID) مناسب محسوب شوند. به طور خلاصه باید گفت که شبکههای عصبی شعاعی پایه در واقع نوعی از شبکههای عصبی پیشخور با تابع فعالسازی و ویژگیهای متفاوت هستند.
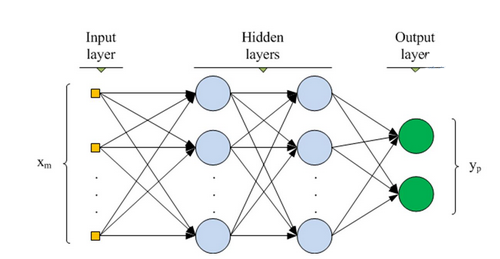
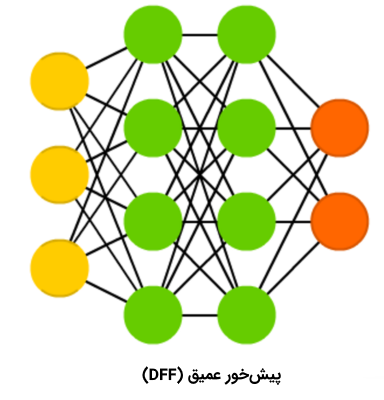
شبکه عصبی پیشخور عمیق
«شبکه عصبی پیشخور عمیق» (Deep Feed Forward Neural Networks | DFF)، در اوایل دهه ۹۰ میلادی، مقدمهای بر بحث شبکههای عصبی شد. این نوع از شبکههای عصبی نیز شبکههای عصبی پیشخور هستند، ولی بیش از یک «لایه پنهان» (Hidden Layer) دارند. سوالی که در این وهله پیش میآید آن است که تفاوت این نوع از شبکههای عصبی با شبکههای عصبی پیشخور سنتی در چیست؟
در هنگام آموزش دادن یک شبکه عصبی پیشخور، تنها بخش کوچکی از خطا به لایه پیشین پاس داده میشود. به همین دلیل، استفاده از لایههای بیشتر، منجر به رشد نمایی زمان آموزش میشود و همین موضوع، موجب میشود که شبکههای عصبی پیشخور عمیق، عملا بدون کاربرد و غیر عملی باشند. در اوایل سال دو هزار میلادی، رویکردهایی توسعه پیدا کردند که امکان آموزش دادن یک شبکه عصبی پیشخور عمیق (DFF) را به صورت موثر فراهم میکردند. امروزه، این شبکههای عصبی، هسته سیستمهای یادگیری ماشین مدرن را تشکیل میدهند و هدفی مشابه با هدف شبکههای عصبی پیشخور (FF) را پوشش میدهند؛ اما نتایج بهتری را دربردارند.
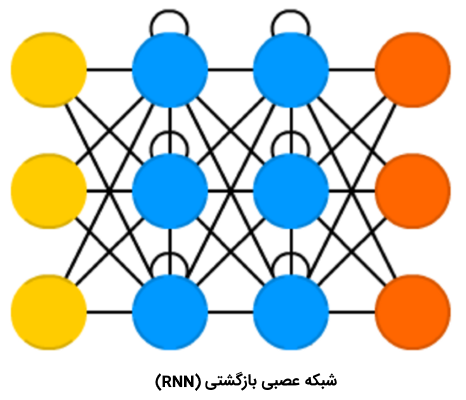
شبکههای عصبی بازگشتی
«شبکههای عصبی بازگشتی» (Recurrent Neural Networks | RNN) نوع متفاوتی از سلولها با عنوان «سلولهای بازگشتی» (Recurrent Cells) را معرفی میکنند. اولین شبکه از این نوع، «شبکه جردن» (Jordan Network) است؛ در این نوع از شبکه، هر یک از سلولهای پنهان، خروجی خود را با تاخیر ثابت – یک یا تعداد بیشتری تکرار- دریافت میکنند. صرف نظر از این موضوع، شبکه جردن مشابه با شبکههای عصبی پیشخور متداول بود.https://beta.kaprila.com/a/templates_ver2/templates.php?ref=blog.faradars&id=string-1&w=760&h=140&t=string&bg=fffff3&hover=ffffcb&rows=3&cid=2021,33,1651&wr=score,score,score_3
البته، تغییرات گوناگونی مانند پاس دادن حالت به «گرههای ورودی» (Input Nodes)، تأخیر متغیرها و دیگر موارد در این نوع از شبکهها اتفاق افتاده، اما ایده اصلی به همان صورت باقی مانده است. این نوع از شبکههای عصبی (NN) اساسا هنگامی استفاده میشوند که «زمینه» (Context) مهم است و در واقع یعنی هنگامی که تصمیمگیریها از تکرارهای قبلی یا نمونهها، میتواند نمونههای کنونی را تحت تاثیر قرار دهد. به عنوان مثالی متداول از این نوع از زمینهها، میتوان به «متن» (Text) اشاره کرد. در متن، یک کلمه را میتوان تنها در زمینه کلمه یا جمله پیشین تحلیل کرد.
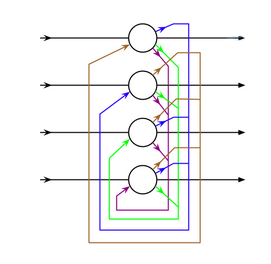
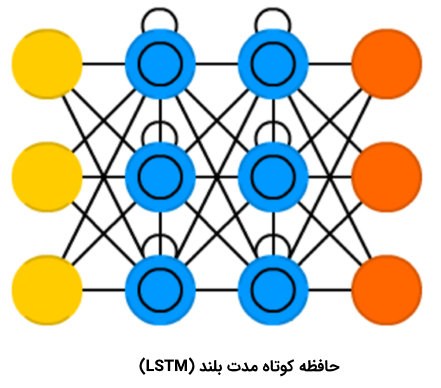
حافظه کوتاه مدت بلند
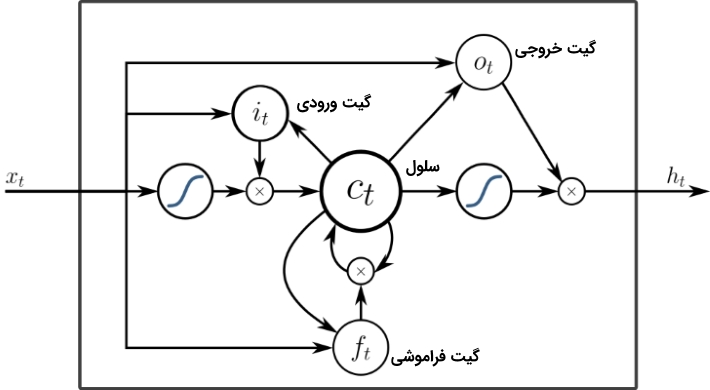
«حافظه کوتاه مدت بلند» (Long/Short Term Memory | LSTM) نوع جدیدی از «سلول حافظه» (Memory Cell) را معرفی میکند. این سلول میتواند دادهها را هنگامی که دارای شکاف زمانی (یا تاخیر زمانی) هستند، پردازش کند. شبکه عصبی پیشخور میتواند متن را با «به خاطر سپردن» ده کلمه پیشین پردازش کند. این در حالی است که LSTM میتواند قابهای ویدئو را با «به خاطر سپردن» چیزی که در قابهای بسیار پیشین اتفاق افتاده است پردازش کند. شبکههای LSTM به طور گستردهای برای «بازشناسی گفتار» (Speech Recognition) و «بازشناسی نوشتار» (Writing Recognition) مورد استفاده قرار میگیرند. سلولهای حافظه اساسا ترکیبی از یک جفت عنصر که به آنها گیت گفته میشود هستند. این عنصرها، بازگشتی هستند و چگونگی به یاد آوردن و فراموش کردن اطلاعات را کنترل میکنند. ساختار این نوع از شبکهها، در تصویر زیر به خوبی مشخص است. این نکته که هیچ تابع فعالسازی بین بلوکها وجود ندارد نیز شایان توجه است.
Xهای موجود در نمودار، گیتها هستند و وزن و گاهی تابع فعالسازی خود را دارند. برای هر نمونه، Xها تصمیم میگیرند دادهها را به جلو پاس دهند یا خیر، حافظه را پاک کنند یا نه و به همین ترتیب. گیت ورودی، تصمیم میگیرد که چه میزان اطلاعات از آخرین نمونه در حافظه نگهداری میشود. گیت خروجی میزان دادههای پاس داده شده به لایه بعدی را تنظیم میکند و گیت فراموشی، نرخ خارج شدن از موارد ذخیره شده در حافظه را کنترل میکند. آنچه بیان شد، یک شکل بسیار ساده از سلولهای LSTM است و معماریهای متعدد دیگری نیز برای این نوع از شبکههای عصبی، موجود است.
شبکه عصبی واحد بازگشتی گِیتی
«واحد بازگشتی گیتی» (Gated Recurrent Unit | GRU) نوعی از LSTM با گیتها و دوره زمانی متفاوت است. این نوع از شبکه عصبی ساده به نظر میآید. در حقیقت، فقدان گیت خروجی، تکرار چندین باره یک خروجی مشابه را برای ورودیها سادهتر میسازد. این نوع از شبکههای عصبی بازگشتی در حال حاضر بیشتر در «موتور متن به گفتار» (Speech Synthesis) و «ترکیب صدا» (Music Synthesis) به کار میرود. البته، ترکیب واقعی LSTM با GRU اندکی متفاوت است. زیرا، همه گیتهای LSTM در یک گیت که به آن گیت به روز رسانی گفته میشود ترکیب شدهاند و گیت «بازشناسی» (Reset) از نزدیک به ورودی گره خورده است. GRUها نسبت به LSTMها کمتر از منابع استفاده میکنند و اثر مشابهی را دارند.
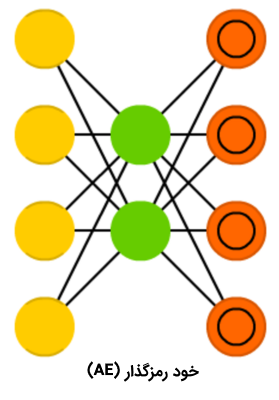
شبکه عصبی خود رمزگذار
شبکههای عصبی «خود رمزگذار» (Auto Encoder | AE) برای دستهبندی، «خوشهبندی» (Clustering) و «فشردهسازی ویژگیها» (Feature Compression) استفاده میشوند. هنگامی که یک شبکه عصبی پیشخور برای دستهبندی آموزش داده میشود، باید نمونههای X در Y دسته به عنوان خوراک داده شوند و انتظار میرود یکی از سلولهای Y فعالسازی شده باشد. به این مورد، «یادگیری نظارت شده» (Supervised Learning) گفته میشود. از سوی دیگر، شبکههای عصبی خود رمزگذار را میتوان بدون نظارت، آموزش داد. با توجه به ساختار این شبکهها (که در آن تعداد لایههای پنهان کوچکتر از تعداد سلولهای ورودی است و تعداد سلولهای خروجی برابر با سلولهای ورودی است) و اینکه AE به نوعی آموزش داده میشود که خروجی تا حد امکان به ورودی نزدیک باشد، شبکه عصبی خود رمزگذار مجبور میشود دادهها را تعمیم دهد و به دنبال الگوهای متداول بگردد.
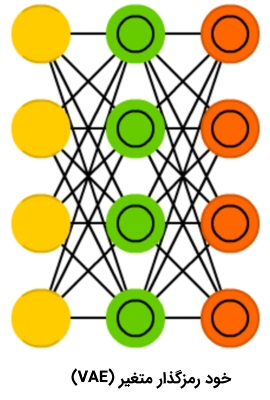
شبکه عصبی خود رمزگذار متغیر
«شبکه عصبی خود رمزگذار متغیر» (Variational Auto Encoder | VAE) در مقایسه با شبکه عصبی خود رمزگذار، احتمالات را به جای ویژگیها فشرده میکند. علارغم تغییرات کوچک که بین دو شبکه عصبی مذکور اتفاق افتاده است، هر یک از این انواع شبکه های عصبی مصنوعی به پرسش متفاوتی پاسخ میدهند. شبکه عصبی خودرمزگذار به پرسش «چگونه میتوان دادهها را تعمیم داد؟» پاسخ میدهد، در حالی که شبکه عصبی خود رمزگذار متغیر به پرسش «اتصال بین دو رویداد چقدر قوی است؟ آیا باید خطا را بین دو رویداد توزیع کرد یا آنها به طور کامل مستقل هستند؟» پاسخ میدهد.
شبکه عصبی خود رمزگذار دینوزینگ
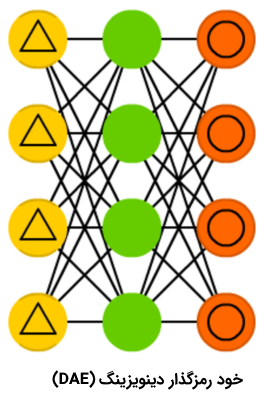
با وجود جالب بودن شبکههای خود رمزگذار، اما این شبکههای عصبی گاهی به جای پیدا کردن مستحکمترین ویژگی، فقط با دادههای ورودی سازگار میشوند (این مورد مثالی از بیشبرازش یا همان Overfitting است). شبکه عصبی «خود رمزگذار دینوزینگ» (Denoising AutoEncoder | DAE) اندکی نویز به سلول ورودی اضافه میکنند. با این کار، شبکه عصبی خود رمزگذار دینوزینگ، مجبور میشود که خروجی را از یک ورودی نویزی، مجددا بسازد و آن را عمومیتر کند و ویژگیهای متداول بیشتری را انتخاب کند.
اینترنت اشیا مفهومی است که امروزه به آن توجه بسیار زیادی می شود. این اینترنت به میلیون ها دستگاه الکتریکی و الکترونیکی در سراسر جهان اشاره دارد که به اینترنت متصل شده اند. این اشیا با هم تشکیل شبکه داده اند و داده های مختلف را با یکدیگر به اشتراک می گذارند.
وایرلس شدن شبکه ها، کمک بزرگی به گسترش و پیشرفت IoT کرده است. برای مشاهده قیمت تجهیزات اکتیو شبکه می توانید به سایت راندنو مراجعه نمایید.
اتصال اشیا به اینترنت در کنار سایر حسگرها، سبب افزایش هوشمندی آن ها نیز می شود. به کمک این فناوری، اشیا با یکدیگر تعامل بیشتری دارند و مداخلات انسانی کاهش می یابد. امروزه IoT به کمک صنایع زیادی همچون کشاورزی، تولیدی، بهداشت، درمان و … آمده است.
در این مقاله به بررسی مفهوم اینترنت اشیا به زبان ساده خواهیم پرداخت و به کاربردهای آن نیز اشاره خواهیم کرد. با مجله راندنو همراه باشید…
اینترنت اشیا (Internet of Things) و یا اینترنت چیزها که به اختصار IoT نیز نامیده می شود، مفهومی است که به گسترش اینترنت و افزایش قدرت آن می پردازد. در این تعریف، اینترنت از دستگاه هایی همچون کامپیوتر و گوشی های هوشمند فراتر می رود و طیف وسیعی از اشیا را به خود اختصاص می دهد.
برای این که بتوانیم مفهوم IoT را به زبان ساده تر بیان کنیم، به یک مثال ساده اشاره خواهیم کرد:
پیش از ورود گوشی های هوشمند، گوشی های معمولی تنها امکان برقراری تماس تلفنی و یا ارسال پیامک را داشتند. با پیشرفت تکنولوژی گوشی های موبایل و به کمک اینترنت، اکنون می توان به گوش دادن موسیقی، تماشای فیلم، خواندن کتاب و … پرداخت.
با اتصال اشیا به اینترنت، کارایی آن ها افزایش می یابد. در حال حاضر بدون وجود اینترنت، بسیاری از گجت ها و دستگاه های الکترونیکی کارایی چندانی ندارند.
برای توضیح مفهوم IoT در یک جمله می توان گفت، IoT یعنی همه چیز در همه جای جهان به اینترنت متصل شوند.
IoT از شش مؤلفه زیر تشکیل شده است:
حسگرها: داده ها توسط حسگرها جمع آوری می شوند.
اتصالات: این داده ها توسط اتصالات مختلف به پایگاه داده منتقل می شوند.
ابر: این بخش همان پایگاه داده است که اطلاعات در آن پردازش می شود.
تحلیل داده: داده ها به طور کامل تحلیل می شوند. دانش و اطلاعاتی که از تحلیل داده به دست می آید، آماده می شود.
رابط کاربری: اطلاعات آماده شده توسط رابط کاربری در اختیار مصرف کننده قرار می گیرد. مصرف کننده نیز اقداماتی را انجام می دهد که اطلاعات به صورت معکوس به دستگاه برمی گردد.
محرک ها: اقدامات هوشمند توسط محرک ها انجام می شود. این محرک ها اقدامات لازم را بدون نیاز به کاربر انجام می دهند.
اینترنت اشیا چیست؟
چند نمونه از اینترنت اشیا
هر جسمی که بتوان آن را به اینترنت متصل کرد و آن جسم نیز بتواند بدون دخالت انسان، اطلاعاتی را در شبکه به اشتراک بگذارد، جزئی از این اینترنت محسوب می شود. در این مثال، یک گوشی هوشمند و یا رایانه جزئی از این نوع اینترنت محسوب نمی شوند زیرا در حالت عادی امکان اتصال آن ها به اینترنت وجود دارد.
هوشمندسازی منازل
یک لامپ ال ای دی را تصور کنید که به وسیله یک گوشی موبایل هوشمند روشن و خاموش می شود و یا رنگ آن تغییر می کند. این لامپ یک دستگاه اینترنت اشیا محسوب می شود.
تصور کنید سیستم روشنایی خانه، پس از ورودتان فعال شود و لامپ های اتاق خواب با فرا رسیدن شب، کم نور شوند. همه این ها جزئی از این نوع اینترنت به شمار می آیند.
به کمک IoT در خانه می توانید دوربین مدار بسته خود را نیز کنترل کنید. کاربران گرامی می توانید برای خرید انواع دوربین مداربسته همین حالا اقدام نمایید.
حسگرهای حرکتی که در دفترهای کار به اینترنت متصل می شوند، یک نوع IoT محسوب می شوند.
نظم شهری و نورپردازی شهر
چراغ خیابانی و روشنایی معابر و بزرگراه ها که از طریق کامپیوترهای از راه دور کنترل می شوند نیز، می توان جزئی از IoT دانست.
موتور جت
یک دستگاه از مجموعه این نوع اینترنت می تواند به سادگی یک وسیله بازی و یا به پیچیدگی یک موتور جت باشد. موتورهای جت نوعی IoT هستند که از مؤلفه های کوچک تر اینترنت اشیا تشکیل شده اند. موتور جت به میلیون ها حسگر مجهز شده است که داده ها را جمع آوری و پردازش می کند.
خودروی بی سرنشین
خودروهای هوشمند و مجهز به این نوع اینترنت نیز وجود دارند که می توانند به امنیت سرنشینان کمک شایانی کنند. این خودروها اطلاعات زیادی را در اختیار رانندگان قرار می دهند و سنسورهای تعبیه شده در آنها، راننده را از موانع فیزیکی سر راه، شرایط جوی و … آگاه می سازد و در صورت بروز مشکل، به طور اتوماتیک با خودروهای امدادرسان و یا اورژانس تماس می گیرد.
هوشمندسازی کشاورزی
IoT در کشاورزی می تواند مربوط به بررسی سنسورهای دما، رطوبت، جمع آوری داده ها، بررسی های مربوط به تولید، مدیریت دورریزها و … باشد.
هوشمندسازی کشاورزی
فناوری اینترنت در پزشکی
IoT در پزشکی یکی از مهم ترین نمونه های این مفهوم به شمار می آید. این فناوری در صنعت پزشکی سبب بهبود مانیتورینگ، گزارش گیری، افزایش دقت در تشخیص، صرفه جویی در هزینه ها، طبقه بندی، آنالیز داده ها و … می شود.
فناوری اینترنت در پزشکی
شهر هوشمند
در ابعاد بزرگ تر می توان به پروژه های شهر هوشمند اشاره کرد که در آن مجموعه ای از حسگرها به کنترل محیط توسط انسان کمک می کنند.
مفهومی به نام اینترنت اشیا صنعتی وجود دارد که به آن IIoT نیز گفته می شود. این مفهوم به این نوع اینترنت در زمینه کسب و کار اشاره می کند. این مفهوم نیز همانند مفهوم عادی IoT است. با این تفاوت که در آن از هوش مصنوعی، اندازه گیری داده ها، تحلیل اطلاعات، بهینه سازی و … نیز استفاده می شود. اینترنت اشیا صنعتی می تواند بسیار بزرگ تر و گسترده تر باشد.
استفاده از IoT صنعتی سبب افزایش درآمد، کاهش هزینه ها، صرفه جویی در زمان و افزایش کارایی نیروی کار می شود.
شهر هوشمند
چرا امنیت اینترنت اشیا مهم است؟
در مبحث این نوع اینترنت، حفاظت داده ها و امنیت آن ها مسئله مهمی است. سیستم های IoT می بایست در مقابل تهدیدها و بدافزارها از خود مقاومت نشان دهند. در غیر این صورت، کلیه سیستم با اتصال به یک بدافزار و یا دستگاه غیرمجاز، از کار می افتد.
بالا بردن امنیت اینترنت اشیا سبب حفاظت از حریم شخصی نیز می شود. زیرا در این صورت، محرمانگی داده ها حفظ می شود و کنترل اشیا نیز تنها برعهده شما خواهد بود.
برای تأمین امنیت اینترنت باید چند مورد را مورد توجه قرار داد:
رعایت استانداردها و پروتکل های ساخت
به روزرسانی و مدیریت صحیح
مقاومت فیزیکی
آگاه بودن کاربر و دانش اپراتور
چرا امنیت اینترنت اشیا مهم است؟
اهمیت اینترنت اشیا چیست؟
زمانی که تمامی اشیا به وسیله اینترنت به یکدیگر متصل می شوند، می توانند اطلاعات مختلف را با هم به اشتراک بگذارند و به طور همزمان، کارهایی را انجام دهند.
اگر اشیا توانایی دریافت و ارسال اطلاعات را داشته باشند، کارایی آنها افزایش می یابد و هوشمندتر می شوند. هوشمندسازی اشیا یک ویژگی بسیار خوب به شمار می آید که بشر همواره در پی آن بوده است. به طور کلی اشیا به سه دسته مختلف تقسیم می شوند:
اشیایی که تنها اطلاعات را جمع آوری می کنند و برای ارسال آماده می کنند.
اشیایی که اطلاعات ارسالی را دریافت و به آن ها عمل می کنند.
اشیایی که هر دو کار بالا را همزمان با هم انجام می دهند.
خطرات استفاده از اینترنت اشیا
IoT مزایای بسیار زیادی دارد و استفاده از آن سطح کیفیت زندگی افراد را بهبود می بخشد. با این حال استفاده از آن معایبی نیز برای مصرف کنندگان و شرکت ها به دنبال دارد.
در شبکه هایی که IoT برقرار شده است، اطلاعات زیادی منتقل و جمع آوری می شود. این اطلاعات ممکن است مورد سوء استفاده قرار بگیرد. به عنوان مثال، هنگامی که در سازمان ها از دوربین مداربسته استفاده می شود، اطلاعات ضبط شده در آن از طریق سیگنال های رادیویی به تلفن یا کامپیوتر صاحبان منتقل می شود.
این اطلاعات رمزگذاری شده نیست و ممکن است توسط افرادی غیر از مالک اصلی مورد استفاده قرار بگیرد. برای کاهش خطرات اینترنت اشیا باید اقداماتی صورت بگیرد تا سطح امنیت اطلاعات افزایش پیدا کند. به عنوان مثال، تمامی اطلاعات انتقالی باید کدگذاری شده باشند.
کاربرد اینترنت اشیا
یکی از شرکت های فعال در زمینه IoT اظهار داشته است که در پایان امسال بیش از ۸ میلیارد دستگاه در شبکه اینترنت اشیا قرار می گیرند. اینترنت چیزها شامل تعداد زیادی دستگاه می شود که به اینترنت وصل می شوند. IoT به کمک جمع آوری و سامان دهی اطلاعات، جاسازی سی پی یو و منابع انرژی می تواند همه چیز را به شبکه متصل کند.
IoT در ساختمان ها، کارخانه ها و … کاربرد ویژه ای دارد. این سیستم وظیفه جمع آوری اطلاعات، تنظیم اکوسیستم های سازمانی و … را برعهده دارد. از IoT در زمینه های رصد محیط زیست و برنامه ریزی های شهری نیز استفاده می شود. از سوی دیگر سیستم های هوشمند می تواند بسیاری از عادت های مصرف کنندگان را تغییر دهد.
IoT در زمینه سنجش بیماری در علم پزشکی می تواند با آنالیز ابری اطلاعات، به کاربران اجازه مطالعه DNA و دیگر مولکول ها را بدهد.
سامانه ترابری هوشمند هدف بعدی شرکت های فعال در زمینه اینترنت اشیا است. زیرا هوشمندسازی این بخش کمک بسیار زیادی به بشریت خواهد کرد.
کاربرد دیگر IoT، افزایش ویژگی های امنیتی خانه و اتوماسیون خانگی است.
در رسانه نیز IoT می تواند یک فرصت مناسب برای جمع آور اطلاعات و تجزیه و تحلیل داده ها باشد.
نظارت و کنترل عملیات زیرساخت های شهری می تواند به راحتی توسط IoT صورت بگیرد. به عنوان مثال، کنترل فرایند ساخت پل ها، نیروگاه ها، خطوط راه آهن و … کاربردهای کلیدی IoT هستند.
مدیریت انرژی و سیستم های یکپارچه سازی حسگرها و محرک ها به شبکه های اینترنت متصل هستند. استفاده از IoT در بهینه سازی مصرف انرژی بسیار مؤثر است.
مسائل حقوقی IoT
در برقراری IoT یک سری سیاست ها باید رعایت شود. IoT نباید حریم خصوصی و حقوق بشری را نقض کند یا مانع آزادی های فردی و اجتماعی شود. افراد باید کنترل داده های شخصی خود که توسط IoT صورت می گیرد را، در اختیار داشته باشند.
میزان اطلاعات زیاد است و ارتباطات به صورت خودکار صورت می گیرد. به همین دلیل بهتر است اپراتور بر آن ها نظارت داشته باشد. برخی از مسائل باید پیش از برقراری سیستم های اینترنت اشیا مورد بحث قرار بگیرد. به عنوان مثال، پاسخ به این پرسش که مالک اطلاعات چه کسی است یا مسئولیت اینترنت اشیا را چه کسی برعهده می گیرد، بسیار مهم است.
تاریخچه IOT
ایده اضافه کردن حسگرهای مختلف و ایجاد یک هوش مصنوعی برای اشیا، در سال های ۱۹۸۰ الی ۱۹۹۰ مطرح شد. این تکنولوژی پیشرفت کندی داشت. اولین فاز اجرایی این پروژه در شرکت کوکاکولا و مربوط به یک ماشین فروش بود.
دلیل کند پیش رفتن این تکنولوژی، آماده نبودن زیر ساخت های آن بود. تراشه هایی که برای این کار عرضه می شد، بسیار بزرگ و حجیم بود. به همین دلیل تمامی اشیا نمی توانستد با یکدیگر در تعامل باشند.
IoT به تراشه هایی ارزان قیمت نیاز دارد که در مصرف انرژی صرفه جویی کنند و هم چنین امکان اتصال آن ها به میلیون ها دستگاه وجود داشته باشد. به همین دلیل از تراشه های RFID استفاده شد. امروزه حسگرهایی که به اشیا اضافه می شوند، ارزان هستند و هزینه کمی دارند.
تاریخچه IoT
اولین استفاده از IOT
کوین اشتون در سال ۱۹۹۹ برای اولین بار از عبارت اینترنت اشیا در جهان استفاده کرد.
از IOT در ابتدا تنها در کارخانه ها و مراکز صنعتی استفاده می شد. در این زمان یکی از زیر مجموعه های IoT یعنی ماشین به ماشین پدید آمد.
این اینترنت فناوری گسترده ای است و گسترده تر نیز خواهد شد. در حال حاضر کل دستگاه هایی که در IoT وجود دارند، از تعداد کل انسان ها بیشتر است.
چه شرکت هایی در زمینه اینترنت اشیا فعال هستند؟
درحال حاضر بسیاری از شرکت ها در حوزه IOT فعالیت می کنند. صنایع بزرگ و کوچک زیادی همچون مراکز بهداشتی و درمانی، مراکز آموزشی و پژوهشی، خطوط تولید و … از این تکنولوژی استفاده می کنند. شرکت های زیر به صورت تخصصی در زمینه IoT فعالیت می کنند:
هواوی
پی تی سی
سیسکو
ساینس سافت
آی بی ام
اگزاجایل
بوش آی او تی سنسور
جی ای دیجیتال
اس آپ
زیمنس آی او تی آنالیتیکس
سوالات متداول
کاربرد اینترنت اشیا چیست؟
مصرف کنندگان در حوزه این اینترنت به سه گروه تقسیم بندی می شوند:
کسب و کارها که به کمک IOT بهبود می یابند.
دولت هایی که هزینه آن ها کاهش پیدا می کند و کیفیت زندگی شهروندانشان افزایش می یابد.
شهروندانی که از این تکنولوژی استفاده می کنند و انجام بسیاری از امور برای آن ها ساده تر می شود.
مزایای استفاده از IOT چیست؟
استفاده از IoT سبب افزایش دقت، کاهش نیاز به منابع انسانی، افزایش کارایی، بهینه شدن منابع، صرفه جویی در زمان و … می شود.
معایب استفاده از اینترنت اشیا چیست؟
این تکنولوژی ممکن است مورد حمله هکرها قرار بگیرد زیرا در بستر شبکه قرار گرفته است. در نتیجه احتمال دارد حریم خصوصی و شخصی شکسته شود. طراحی و اجرای اینترنت اشیا پیچیدگی هایی دارد. هم چنین بسیاری از مشاغل با کاهش منابع انسانی از بین می روند.
در اینترنت اشیا چه چیزهایی هوشمند می شوند؟
بستر اینترنت می تواند برای طیف وسیعی از اشیا فراهم شود. از لوازم خانگی مانند اجاق گاز، قهوه ساز، یخچال، لباسشویی و … گرفته تا تجهیزات در صنعت کشاورزی هم چون سنسورهای نور، سنسورهای دما، رطوبت و … هوشمند می شوند. گزارش گیری و مانیتورینگ در صنعت پزشکی و درمانی نیز تحت تأثیر این اینترنت قرار می گیرند.
چگونه از اینترنت اشیا استفاده کنیم؟
IoT در ایران هنوز به پیشرفت کشورهایی همچون آمریکا، چین، آلمان، برزیل، کره جنوبی، هند و سنگاپور نرسیده است. این مفهوم در ایران اغلب در زمینه ساختمان سازی مورد استفاده قرار می گیرد. IoT برای لوازم خانگی مانند تلویزیون، یخچال و … نیز در ایران جا افتاده است.
به طور کلی این مفهوم در ایران هنوز قیمت بالایی دارد. هوشمندسازی تهران و دیگر شهرهای ایران در دستور کار دولت قرار دارد. به زودی شرکت های فعال در این زمینه راهکارهایی جهت توسعه و گسترش IoT در ایران پیشنهاد می دهند. پیش از آن باید از مفاهیم ابتدایی این تکنولوژی استفاده کرد.










{kind=link}
{kind=link}