شبکههای عصبی مصنوعی با الهام گرفتن از عملکرد مغزانسان ایجاد میشوند و در موارد گوناگونی از پزشکی تا اقتصاد کاربرد دارند.
کامپیوتر بهتر است یا مغز؟ اگر از افراد سؤال کنید کهآیا دوست دارند مغزی شبیه به کامپیوتر داشته باشند، فورا جواب مثبت میدهند. امااگر به فعالیتهای دو دههی اخیر دانشمندان در این زمینه نگاه کنید، متوجه میشویدکه آنها سعی دارند کامپیوترهایی بسازند که شبیه به مغز عمل کند. اما پرسش ایناست که چگونه؟ آنها به کمک شبکههای عصبی این کار را میکنند.شبکههای عصبی برنامههایی کامپیوتری هستند که از صدها، هزاران یا میلیونها سلولمغز مصنوعی تشکیل شدهاند که شبیه به مغز انسان، عمل یادگیری و رفتاریرا انجام میدهد. در اینجا قصد داریم به ماهیت دقیقتر شبکههای عصبی و چگونگی کارکردآنها بهطور جزئیتر بپردازیم.
کامپیوتر و مغز چیزهای مشترکزیادی دارند؛ اما اساسا متفاوت هستند. اگر ما انعطافپذیری مغز را با قدرتکامپیوتر ترکیب کنیم چه اتفاقی میافتد؟ احتمالا یک شبکه عصبی فوقالعاده مفید بهدست میآید. این عکس مربوط به همپوشانی اسکن مغزی مؤسسهی ملیNIDA و مؤسسهی ملی سلامت آمریکا با شبکه عصبی سایتexplainthatstuff.comاست.
تفاوت مغز با کامپیوتر
گاهی اوقات پیش میآید که افراد مغز انسان را باکامپیوترهای الکترونیکی مقایسه و شباهتهای آنها را بررسی میکنند. یک مغز عادیحاوی ۱۰۰میلیارد (هیچکس بهطور دقیق نمیداندکه این تعداد چقدر است و تخمین زده میشود که این تعداد بین ۵۰ میلیاردتا نورون است.هر نورون از یک جسم سلولی (یا جسم یاخته که تودهی مرکزی سلول است) با تعدادی از اتصالات مربوط بهآن ساخته شده است: تعداد زیادی دندریتآکسون(خروجی سلول که حامل اطلاعات به خارجسلول است). نورونها آنقدر کوچک هستند که میتوان ۱۰۰ عدد از جسمهایسلولی آنها را در یک میلیمتر قرار داد. گفتنی است که نورونهاتنها سلولهای گلیالیحفاظت و تغذیه نورونهارا برای رشد و کار کردن آنها بر عهده دارند. داخل کامپیوتر، دستگاه کوچکی به نامترانزیستور وجود دارد که عملکردی شبیه به سلول مغزی دارد.جدیدترین و پیشرفتهترین ریزپردازنده حاوی بالغ بر ۲ میلیاردترانزیستور هستند؛ حتی یک ریزپردازندهی ابتدایی، دارای چیزی حدود مدار مجتمع (آیسی) با مساحت تنها ۲۵ میلیمتر مربع(کوچکتر از یک تمبر پستی) قرار داده شدهاند.
یک نورون، ساختار بنیادین یک سلولمغزی است که جسم سلولی مرکزی، دندریتها (که به جسم سلولی منتهی میشوند) و آکسون (که از جسم سلولی خارج میشود) رانشان میدهد. این تصویر متعلق دبه مؤسسهی ملی NIDA و مؤسسهی ملی سلامت آمریکا است.
این همان جایی است که مقایسهی بین کامپیوتر و مغزشروع میشود و بهپایان میرسد؛ چرا که این دو پدیده کاملا باهم متفاوتاند. تفاوتتنها مربوط به این نمیشود که کامپیوترها جعبههای فلزی سردی هستند که پر از اعدادباینری (۰ و ۱) هستند و اینکه مغز جسم زنده و گرمی در نظرگرفته میشود که پر از احساسات، افکار و خاطرات ما است. تفاوت اصلی اینجا است که نحوهیفکر کردن کامپیوتر ومغز متفاوت است. نحوهی چینش ترانزیستورهای کامپیوتر نسبتا ساده و به شکل زنجیرههایسریالی (هر تزانزیستور به دو یا سه ترانزیستور دیگر در ترتیبی به نام دروازهیمنطقی متصل است) است، درحالیکه نورونها در مغز به نحوی بسیار پیچیدهو موازی به یکدیگر متصلاند (هر نورون شاید به حدود ۱۰ هزارنورون مجاور خود اتصال داشته باشد).
تفاوت ساختار اصلی بین کامپیوتر (با چندصد میلیونترانزیستور متصلشده به روشی ساده) و مغز (شاید ۱۰ تا ۱۰۰ برابر پیچیدهتر از روش اتصال کامپیوتر) چیزی است که باعث میشود این دوآنقدر متفاوت فکر کنند. کامپیوتر برای ذخیره کردن مقادیر زیادی از اطلاعات بیمعنی(برای کامپیوتر) و مرتب کردن دوبارهی این اطلاعات با توجه به دستورالعملها(برنامهها) طراحی شده است، درصورتیکه مغز فرآیندیادگیری آهسته و با متدی میدانی دارد که ماهها یا سالها طول میکشد که یک چیزپیچیده را کاملا درک کند. اما مغز برخلافکامپیوتر، میتواند بهطور همزمان اطلاعات را در راههای جدیدی ترکیب کند (مثلآثار بتهوون یا شکسپیر که ناشی از خلاقیت بود)، الگوهای اصلی راشناسایی کند، اتصالات جدیدی بسازد و چیزهایی را که یاد گرفته است با بینش مختلفیببیند.
مغز الکترونیکی؟ نه کاملا. درداخل، یک تراشهی کامپیوتر معمولی است (مربع مرکزی) که از هزاران، میلیونها وشاید حتی میلیاردها سوئیچ الکترونیکی به نام ترانزیستور تشکیل شده، اما تعداد آنهاکمتر از سلولهای داخل مغز انسان است. عکس اقتباسشده از مرکز تحقیقات گلن ناسااست.
شبکه عصبی چیست؟
شبیهسازی(کپی کردن ساده و درعینحال پایدار)بسیاری از سلولهای مغزی متصل داخل یک کامپیوتر است تا بتوان اعمال یادگیری،شناسایی الگوهاتصمیمگیریانسانگونه را انجام داد. نکتهی جالب توجه درمورد شبکهی عصبی این استکه نیازی نیست آن را برای یادگیری صریح، برنامهریزی کنید.این شبکه در واقعمیتواند همهچیز را مانند مغز انسان، خودش یاد بگیرد.
آیا شبیه شدن کامپیوترها به مغز انسان اتفاق خارقالعادهای نخواهدبود؟ این همان بزنگاهی است که شبکههای عصبی وارد عرصه میشوند
اما این شبکهی عصبی، مغز نیست. در نظر داشتن ایننکته مهم است که شبکههای عصبی عموما شبیهسازهای نرمافزاری هستند که با برنامهنویسیبرای کامپیوترهای بسیار ساده و پیشپاافتاده راه میافتند و با روشهای قبلی خود وبا استفاده از ترانزیستورها و دروازههای منطقی خود کار میکنند تا بهمانندمیلیاردها سلول مغزی متصل و موازی رفتار کنند. هیچکس تا به حال حتی تلاش همنکرده است تا کامپیوتری بسازد که با ترانزیستورهایی با ساختار موازی مانند مغزانسان کار کند. بهعبارت دیگر تفاوت شبکهی عصبی با مغز مانند تفاوت مدل کامپیوتریآبوهوا با ابر، برف، و هوای آفتابی درواقعیت است. شبیهسازی کامپیوتر تنها مجموعهایاز متغیرهای جبری و معادلات ریاضی است که آنها را بههم متصل میکند (اعداد ذخیرهشدهدر جعبههایی که مقادیر آنها دائما درحال تغییر است). این شبیهسازیها برایکامپیوترها هیچ معنایی ندارد و تنها برای افرادی که برنامه آنها را مینویسندبامعنا است.
شبکههای عصبی حقیقی و مصنوعی
قبلاز اینکه جلوتر برویم، باید چندین اصطلاح رابررسی کنیم. شبکههای عصبی که به این طریق (شبیهسازی و برنامهنویسی) ساخته میشوند،شبکهی عصبی مصنوعی(ANN) نامیده میشوندتا نسبت به شبکههای عصبی حقیقی (مجموعههای سلولهای مغزی متصل) که داخل مغز ماهستند متمایز شوند. شاید اصطلاحات دیگری مانند ماشینهای اتصال، پردازندههای توزیعشدهیموازی، ماشینهای تفکر و ... نیز به گوش شما خورده باشد، اما در این مقاله تنهاقصد داریم از اصطلاح شبکهی عصبی استفاده کنیم و هر جا این اصطلاح دیده شد، منظورهمان شبکهی عصبی مصنوعی است.
یک شبکه عصبی متشکل از چه چیزهایی است؟
یک شبکه عصبی معمولی دهها، صدها،َ هزاران یا حتیمیلیونها نورون مصنوعی به نام واحد دارد که در مجموعهای ازلایهها قرارگرفتهاند که در هرطرف با بقیه لایهها بههم متصلاند. برخی از آنهابا نام واحدهای ورودی شناخته میشوند. این واحدها برای دریافتشکلهای مختلف اطلاعات از دنیای خارجی که شبکه سعی در یادگیری، شناسایی و پردازشآنها دارد، طراحی شدهاند. سایر واحدها که واحدهای خروجی نامیدهمیشوند، در طرف مخالف شبکه قرار دارند و چگونگی واکنش شبکه به اطلاعات یادگرفتهشدهرا مشخص و بررسی میکنند. درمیان واحدهای ورودی و خروجی، واحدهای مخفی وجود دارندکه به همراه این واحدها، اکثریت مغز مصنوعی را تشکیل میدهندبهطور کامل متصلاند؛بدین معنا که هر واحد مخفی و هر واحد خروجی به واحدهای لایههای هرطرف متصل است.اتصال بین واحدها با عددی به نام وزن ارائه میشود. وزن میتواندمثبت (اگر یک واحد، واحددیگر را برانگیخته کند) یا منفی(اگر یک واحد، واحد دیگر را سرکوب یا مهار کند) باشد. هرچقدر میزان وزن بالاترباشد، تأثیر یک واحد بر دیگری بیشتر میشود. این شبیه به راهی است که سلولهایحقیقی مغز در شکافهای کوچکی به نام سیناپس باعث برانگیختگییکدیگر میشوند.
یک شبکه عصبی کاملا متصل، متشکلاز واحدهای ورودی (قرمز)، مخفی (آبی) و خروجی (زرد) است که همه این واحدها به همهواحدهای هرطرف خود متصل هستند. واحدهای ورودی ازسمت چپ وارد میشوند و واحدهای مخفی در وسط را فعال و خروجی را از سمت راستخارج میکنند. قدرت (وزن) اتصال بین هر دو واحد بهتدریج با یادگیریهای شبکهمنطبق میشود.
شبکه عصبی چگونه یاد میگیرد؟
اطلاعات به دو طریق در شبکهی عصبی جریان دارند:زمانی که در حال یادگیری است؛ یا بعد از اینکه عمل یادگیری انجام شد. در این زمانهاالگوهای یادگیری بهوسیلهی واحدهای ورودی وارد شبکه میشوند و لایههای واحدهایمخفی را برانگیخته میکنند و این لایهها به واحدهای خروجی میرسند. به این طراحیرایج، شبکه عصبی پیشخور میگویند. همهی واحدها همیشه شلیک نمیشوند. هر واحدی اطلاعات ورودی را از واحدهای سمتچپ خود دریافت میکند و ورودیها در وزن اتصالات مربوطبه خود ضرب میشوند.هرواحدی تمامی ورودیهایی را که دریافت میکند به این طریق جمع میزند و (در سادهتریننوع شبکه) اگر جمع بیشاز یک مقدار آستانه مشخص شد، این واحدشلیک میکند و واحدهای متصل بهخود را (که در سمت راست هستند) راه میاندازد.
بازخوردوجود داشته باشد؛ همانطور که به کودکان گفته میشود که چه چیزی درست است و چهچیزی غلط. درواقع همهی ما همیشه از بازخورد استفاده میکنیم. زمانی را بهخاطر بیاوریدکه میخواستیم برای اولین بار بازی بولینگ را یاد بگیریم. وقتی شما توپ سنگینیبرمیدارید و آن را پرتاب میکنید، مغز شما بهسرعت چگونگی حرکت توپ و مسیر آن رامشاهده میکند و میزان دقت شما را بررسی میکند. دفعه بعدی که دوباره نوبت شما رسید، اشتباهات دفعه قبلی خود را بهیاد میآوریدو حرکت خود را باتوجه به این اشتباهات اصلاح میکنید و امیدوارید که اینبار توپرا بهتر از قبل پرتاب کنید. بنابراین در این مثال از بازخورد برایمقایسه نتیجه قبلی با نتیجه دلخواه خود استفاده میکنید. این بازخورد تفاوتها رامشخص میکند و تغییراتی در دستور کار شما برای دفعه بعدی ایجاد میکند: باشدتبیشتر پرتاب کردن؛ کمی بهسمت چپ پرتاب کردن؛ دیرتر رها کردن، و غیره. هرچه تفاوتبین نتایج حقیقی و نتایج دلخواه بیشتر و بزرگتر شود، تغییرات نیز بیشتر خواهد شد.
بولینگ: شما باکمک شبکه عصبی داخل مغزتان یاد میگیرید که چگونه چنین مهارتهایی بهدست بیاورید. هردفعه که شما توپ را اشتباه پرتاب میکنید، یاد میگیرید که چهاصلاحاتی باید برای دفعه بعد به کار برید.
شبکههای عصبی نیز بههمین روش چیزهای مختلف را یادمیگیرند. یادگیری شبکههای عصبی با استفادهاز یک روند بازخوردی را پسانتشارگویند. این عمل عبارت است از: مقایسهی خروجی تولیدی یک شبکه با خروجی که دلخواهو مورد انتظار است. از تفاوت بین این دو خروجی، برای تغییر و اصلاحوزنهای اتصالات بین واحدهای شبکه استفاده میشود، با این تفاوت که این روش برعکساست، یعنی از واحدهای خروجی بهسمت واحدهای مخفی و سپس از آنجا بهسمت واحدهایورودی میرویم. پسانتشار با کاهش تفاوت بین خروجی واقعی و خروجی دلخواه، تاحدی کهاین دو خروجی یکسان شوند، جلو میرود تا شبکهی عصبی دقیقا همانطوری که باید وانتظار میرود، کار کند.
شبکه عصبی در عمل چگونه کار میکند؟
زمانی که شبکه توسط نمونههای یادگیری کافی، آموزشداده شد، به نقطهای میرسد که میتوان یک سری جدید از ورودیها را وارد آن کرد کهقبلا آنها را ندیده باشد و واکنش شبکه به این ورودیهای جدید را مشاهده کرد. بهعنوانمثال، فرض کنید که با نشان دادن تصاویر زیادی از صندلی و میز درحال آموزش دادن یکشبکه هستید و بهگونهای به شبکه آموزش میدهید که کامل مفاهیم شما را درک کند وبه شما بگوید که تصویر متعلق به صندلی است یا میز. وقتی شما بهاندازهی کافی،تصویر صندلی و میز را به این شبکه نشان دادید؛ مثلا تعداد ۲۵ میز و ۲۵صندلی، طرح جدیدی از صندلی یا میز را به آن نشان میدهید که قبلا آن را ندیده باشدو میبینید که شبکهی شما چه واکنشی نشان میدهد. بسته به نوع آموزش شما، شبکهتلاش میکند که نمونهی جدید را دستهبندی کند و بگوید که آیا نمونه، تصویر صندلیاست یا میز. شبکه کار دستهبندی را مانند انسان و با استفادهاز تجارب گذشته انجاممیدهد. درواقع شما به کامپیوتر یاد دادهایدکه چگونه لوازم را شناسایی کند.
البته این بدین معنی نیست که شبکهی عصبی بتواند بهنمونهها نگاه کند و فورا مثل انسان به آنها واکنش درست نشان دهد. مثالی را کهزدیم درنظر بگیرید: این شبکه به میز یا صندلی نگاه نمیکند. ورودیهای شبکه اعداد باینریهستند: هر واحد ورودی یا ۰ است یا ۱. بنابراین اگرشما ۵ واحد ورودی داشته باشید، میتوانید اطلاعات ۵مشخصه متفاوت صندلیهای مختلف را با استفاده از جواب باینری (بله/خیر) پاسخ دهید.سؤالات ممکن است به این طریق باشند:
آیا این شیء پشتی دارد؟
آیا قسمت بالایی دارد؟
آیا تکیهگاه آن نرم است؟
آیا میتوان برای مدت طولانی بهطور آسوده روی آن نشست؟
آیا میتوان چیزهای بسیاری روی آن قرار داد؟
اگر نمونهی ارائهشده یک صندلی معمولی باشد، جواب میشود:بله؛ خیر؛ بله؛ بله؛ خیر با کد باینری ۱۰۱۱۰. اگر نمونهیک میز معمولی باشد، جواب میشود: خیر؛ بله؛ خیر؛ خیر؛ بله با کد باینری ۰۱۰۰۱. بنابراین شبکه به اعداد باینری نگاه میکند و ازطریق خروجی این اعدادتشخیص میدهد که شی صندلی است یا میز.
از شبکههای عصبی برای چه کاری استفاده میشود؟
احتمالا باتوجه به این مثال، میتوانید کاربردهایمختلفی برای شبکههای عصبی متصور شوید که عبارتاند از شناسایی الگوهاو تصمیمگیریهای ساده درمورد آنها. در هواپیماها از یک شبکهیعصبی میتوان بهعنوان یک خلبان خودکار استفاده کرد. در هواپیما، واحدهای ورودی،سیگنالهای دستوری مختلف از کابین خلبان را میخوانند و واحدهای خروجی هم کنترل وهدایت هواپیما را باتوجه به سیگنالها تنظیم میکنند. درداخل یک کارخانه برایکنترل کیفیت، میتوان از شبکهی عصبی استفاده کرد. اگر کار کارخانه تولید موادشوینده لباس در پروسهای پیچیده و شیمیایی باشد، اندازهگیری مادهی شیمیایی نهاییازطریق راههای مختلفی (رنگ، میزان اسیدیته، غلظت، و غیره) انجام میشود.درنهایت این اندازهگیریها بهعنوان ورودی به شبکه عصبیوارد میشوند و سپس شبکه درمورد اینکه آیا ترکیب آنها قابل قبول است یا خیر،تصمیمگیری میکند.
شبکهی عصبی در موارد امنیتی نیز استفادههای زیادیدارد. فرض کنید ادارهی بانکی را برعهده دارید که هزاران معامله با کارت اعتباریدر دقیقه ازطریق سیستم کامپیوتری شما انجام میشود. معاملات باید سریعا شناساییشوند تا از کلاهبرداری جلوگیری شود. شبکهی عصبی برای جلوگیری از این کلاهبرداریبسیار مناسب است. ورودیها میتوانند مواردی مثل این سؤالات باشند:
آیا دارندهی کارت واقعا حضور دارد؟
آیا شمارهی پین واردشده صحیح است؟
آیا تعداد ۴ یا ۵ معامله در ۱۰ دقیقه گذشته توسط این کارت صورت گرفته است؟
آیا موارد استفادهاز این کارت، در کشوری خارجاز جایی است کهثبت شده است؟
و سایر موراد مشابه.
یک شبکهی عصبیمیتواند با سرنخهای کافی، معاملات مشکوک را شناسایی کند و به متصدی انسانی خبردهد تا این معاملات را دقیقتر بررسی کند. یک بانک نیز بههمین روش میتواند ازشبکهی عصبی برای تصمیمگیری برای وام دادن به افراد براساس سابقهی کارتاعتباری، درآمد فعلی و اطلاعات و سابقه کاری آنها استفاده کند.
بسیاری ازکارهای روزمره مشمول شناسایی الگوها و استفاده از این الگوها برای تصمیمگیری میشوند،بنابراین شبکههای عصبی میتوانند در بیشمار روش به ما کمک کنند. آنها میتواننددر پیشبینی بازار سهام و ارز، آب و هوا، سیستمهایاسکن راداری که بهطور خودکار هواپیما یا کشتی دشمن را شناسایی میکنند و حتی بهدکترها برای تشخیص بیماریهای پیچیده براساس نشانههای این بیماریها، کمک کنند.درهمین لحظه نیز شبکههای عصبی در کامپیوتر یا موبایل شما وجود دارند. اگر شما ازتلفنهای هوشمندی استفاده میکنید که دستخط شما روی صفحه لمسی را شناسایی میکنند،احتمالا این تلفنها از یک شبکهی عصبی ساده برای تشخیص کاراکترهایی که مینویسید(براساس مشخصههای خاص و ترتیب آنها) استفاده میکند. برخی از نرمافزارهایتشخیص صدا نیز از شبکه عصبی استفاده میکنند.
همچنین برخیاز برنامههای ایمیلی که بهطور خودکار ایمیلهای واقعی را از اسپمها جدا میکنند،از شبکه عصبی استفاده میکنند. شبکههای عصبی در ترجمهی یک زبان به زبان دیگر نیزمؤثر هستند. بهعنوان مثال، ترجمهی خودکار گوگل در چند سال گذشته استفادهی زیادیاز فناوری شبکه عصبی کرده است. گوگل در سال ۲۰۱۶ اعلام کرد کهاز چیزی به نام ماشین ترجمه عصبی برای ترجمه کامل جملههااستفاده میکند که میزان خطای آن از ۵۵ تا ۸۵درصد کاهش یافته است.
رویهم رفته، شبکههای عصبی، سیستمهای کامپیوتری رامفیدتر از قبل کردهاند؛ چراکه آنها را شبیه به مغز انسان کردهاند. شاید اینبار اگر گمان کردید که دوست دارید مغزتان شبیه به کامپیوتر شود، تجدید نظر کنید وخوشحال باشید که چنین شبکهی عصبی کارآمدی در سرتان دارید!
در علم یادگیری ماشین (Machine Learning)، به موضوع طراحی ماشینهایی پرداخته میشود که با استفاده از مثالهای داده شده به آنها و تجربیات خودشان، بیاموزند. در واقع، در این علم تلاش میشود تا با بهرهگیری از الگوریتمها، یک ماشین به شکلی طراحی شود که بدون آنکه صراحتا برنامهریزی و تک تک اقدامات به آن دیکته شود بتواند بیاموزد و عمل کند. در یادگیری ماشین، به جای برنامهنویسی همه چیز، دادهها به یک الگوریتم عمومی داده میشوند و این الگوریتم است که براساس دادههایی که به آن داده شده منطق خود را میسازد. یادگیری ماشین روشهای گوناگونی دارد که از آن جمله میتوان به یادگیری نظارت شده، نظارت نشده و یادگیری تقویتی اشاره کرد. الگوریتمهای مورد استفاده در یادگیری ماشین جزو این سه دسته هستند.
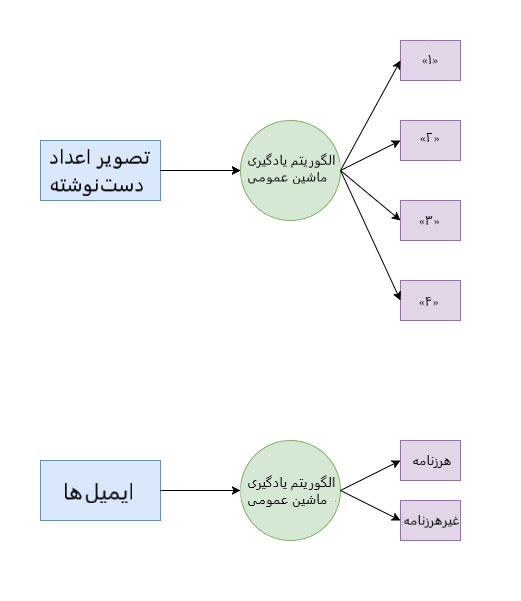
الگوریتم دستهبندی مثالی برای مطلب بیان شده است. این الگوریتم میتواند دادهها را در گروههای (دستههای) مختلف قرار دهد. الگوریتم دستهبندی که برای بازشناسی الفبای دستخط استفاده میشود را میتوان برای دستهبندی ایمیلها به هرزنامه و غیر هرزنامه نیز استفاده کرد.
تام میشل (Tom M. Mitchell) در تعریف یادگیری ماشین میگوید: «(یک برنامه یادگیرنده) برنامه رایانهای است که به آن گفته شده تا از تجربه E مطابق با برخی وظایف T، و کارایی عملکرد P برای وظیفه T که توسط P سنجیده میشود، یاد بگیرد که تجربه E را بهبود ببخشد.»
به عنوان مثالی دیگر، میتوان بازی دوز (چکرز) را فرض کرد.
E: تجربه بازی کردن بازی دوز به دفعات زیاد است.
T: وظیفه انجام بازی دوز است.
P: احتمال آنکه برنامه بتواند بازی بعدی را ببرد است.
مثالهایی از یادگیری ماشین
مثالهای متعددی برای یادگیری ماشین وجود دارند. در اینجا چند مثال از مسائل طبقهبندی زده میشود که در آنها هدف دستهبندی اشیا به مجموعهای مشخص از گروهها است.
تشخیص چهره: شناسایی چهره در یک تصویر (یا تشخیص اینکه آیا چهرهای وجود دارد یا خیر).
فیلتر کردن ایمیلها: دستهبندی ایمیلها در دو دسته هرزنامه و غیر هرزنامه.
تشخیص پزشکی: تشخیص اینکه آیا بیمار مبتلا به یک بیماری است یا خیر.
پیشبینی آب و هوا: پیشبینی اینکه برای مثال فردا باران میبارد یا خیر.
نیازهای یادگیری ماشین
یادگیری ماشین زمینه مطالعاتی است که از هوش مصنوعی سر بر آورده. بشر با استفاده از هوش مصنوعی بهدنبال ساخت ماشینهای بهتر و هوشمند است. اما پژوهشگران در ابتدا به جز چند وظیفه ساده، مانند یافتن کوتاهترین مسیر بین نقطه A و B، در برنامهریزی ماشینها برای انجام وظایف پیچیدهتری که بهطور مداوم با چالش همراه هستند ناتوان بودند. بر همین اساس، ادراکی مبنی بر این شکل گرفت که تنها راه ممکن برای تحقق بخشیدن این مهم، طراحی ماشینهایی است که بتوانند از خودشان یاد بگیرند. ماشین در این رویکرد به مثابه کودکی است که از خودش میآموزد. بنابراین، یادگیری ماشین بهعنوان یک توانایی جدید برای رایانهها مطرح شد. امروزه این علم در بخشهای گوناگون فناوری مورد استفاده قرار میگیرد، و بهرهگیری از آن به اندازهای زیاد شده که افراد اغلب از وجودش در ابزارها و لوازم روزمره خود بیخبرند.
یافتن الگوها در دادههای موجود در سیاره زمین، تنها برای مغز انسان امکانپذیر است. اما هنگامی که حجم دادهها بسیار زیاد میشود و زمان لازم برای انجام محاسبات افزایش مییابد، نیاز به یادگیری ماشین به عنوان علمی مطرح میشود که به افراد در کار با دادههای انبوه در حداقل زمان کمک میکند.
با وجود آنکه مباحث مِهداده (کلان داده/big data) و پردازش ابری به دلیل کاربردی که در جنبههای گوناگون زندگی بشر دارند حائز اهمیت شدهاند، اما در حقیقت یادگیری ماشین فناوری است که به دانشمندان داده در تحلیل بخشهای بزرگ داده، خودکارسازی فرآیندها، بازشناسی الگوها و ارزشآفرینی کمک میکند.
روشی که اکنون برای دادهکاوی استفاده میشود برای سالها مطرح بوده، اما موثر واقع نشده زیرا قدرت رقابتی برای اجرای الگوریتمها نداشته. این در حالی است که امروزه اگر بهعنوان مثال یک الگوریتم یادگیری عمیق با دسترسی به دادههای خوب اجرا شود، خروجی دریافت شده منجر به پیشرفتهای چشمگیری در یادگیری ماشین میشود.
انواع یادگیری ماشین
الگوریتمهای یادگیری ماشین بر سه نوع هستند:
یادگیری نظارت شده
یادگیری نظارت نشده
یادگیری تقویتی
یادگیری نظارت شده
اغلب روشهای یادگیری ماشین از یادگیری نظارت شده استفاده میکنند. در یادگیری ماشین نظارت شده، سیستم تلاش میکند تا از نمونههای پیشینی بیاموزد که در اختیار آن قرار گرفته. به عبارت دیگر، در این نوع یادگیری، سیستم تلاش میکند تا الگوها را بر اساس مثالهای داده شده به آن فرا بگیرد.
به بیان ریاضی، هنگامی که متغیر ورودی (X) و متغیر خروجی (Y) موجودند و میتوان بر اساس آنها از یک الگوریتم برای حصول یک تابع نگاشت ورودی به خروجی استفاده کرد در واقع یادگیری نظارت شده است. تابع نگاشت به صورت (Y = f(X نشان داده میشود.
مثال:
برای باز شدن مساله در ادامه توضیحات بیشتری ارائه میشود. همانطور که پیش از این بیان شد، در یادگیری ماشین مجموعه داده (هایی) به الگوریتم داده میشود و ماشین منطق خود را بر اساس آن مجموعه داده (ها) شکل میدهد. این مجموعه داده دارای سطرها و ستونهایی است. سطرها (که از آنها با عنوان رکورد و نمونه داده نیز یاد میشود) نماینده نمونه دادهها هستند. برای مثال اگر مجموعه داده مربوط به بازیهای فوتبال (وضعیت جوی) باشد، یک سطر حاوی اطلاعات یک بازی خاص است. ستونها (که از آنها با عنوان خصیصه، ویژگی، مشخصه نیز یاد میشود) در واقع ویژگیهایی هستند که هر نمونه داده را توصیف میکنند.https://beta.kaprila.com/a/templates_ver2/templates.php?ref=blog.faradars&id=string-1&w=760&h=140&t=string&bg=fffff3&hover=ffffcb&rows=3&cid=1871,391,2560&wr=cat_2_data_mining,cat_data_mining,cat_2_data_mining
در مثالی که پیشتر بیان شد، مواردی مانند وضعیت هوا شامل ابری بودن یا نبودن، آفتابی بودن یا نبودن، وجود یا عدم وجود مه، بارش یا عدم بارش باران و تاریخ بازی از جمله ویژگیهایی هستند که وضعیت یک مسابقه فوتبال را توصیف میکنند. حال اگر در این مجموعه داده به عنوان مثال، ستونی وجود داشته باشد که مشخص کند برای هر نمونه داده در شرایط جوی موجود برای آن نمونه خاص بازی فوتبال انجام شده یا نشده (برچسبها) اصطلاحا میگوییم مجموعه داده برچسبدار است. اگر آموزش الگوریتم از چنین مجموعه دادهای استفاده شود و به آن آموخته شود که بر اساس نمونه دادههایی که وضعیت آنها مشخص است (بازی فوتبال انجام شده یا نشده)، درباره نمونه دادههایی که وضعیت آنها نامشخص است تصمیمگیری کند، اصطلاحا گفته میشود یادگیری ماشین نظارت شده است.
مسائل یادگیری ماشین نظارت شده قابل تقسیم به دو دسته «دستهبندی» و «رگرسیون» هستند.
دستهبندی: یک مساله، هنگامی دستهبندی محسوب میشود که متغیر خروجی یک دسته یا گروه باشد. برای مثالی از این امر میتوان به تعلق یک نمونه به دستههای «سیاه» یا «سفید» و یک ایمیل به دستههای «هرزنامه» یا «غیر هرزنامه» اشاره کرد.
رگرسیون: یک مساله هنگامی رگرسیون است که متغیر خروجی یک مقدار حقیقی مانند «قد» باشد. در واقع در دستهبندی با متغیرهای گسسته و در رگرسیون با متغیرهای پیوسته کار میشود.
یادگیری نظارت نشده
در یادگیری نظارت نشده، الگوریتم باید خود به تنهایی بهدنبال ساختارهای جالب موجود در دادهها باشد. به بیان ریاضی، یادگیری نظارت نشده مربوط به زمانی است که در مجموعه داده فقط متغیرهای ورودی (X) وجود داشته باشند و هیچ متغیر داده خروجی موجود نباشد. به این نوع یادگیری، نظارت نشده گفته میشود زیرا برخلاف یادگیری نظارت شده، هیچ پاسخ صحیح داده شدهای وجود ندارد و ماشین خود باید به دنبال پاسخ باشد.
به بیان دیگر، هنگامی که الگوریتم برای کار کردن از مجموعه دادهای بهره گیرد که فاقد دادههای برچسبدار (متغیرهای خروجی) است، از مکانیزم دیگری برای یادگیری و تصمیمگیری استفاده میکند. به چنین نوع یادگیری، نظارت نشده گفته میشود. یادگیری نظارت نشده قابل تقسیم به مسائل خوشهبندی و انجمنی است.
قوانین انجمنی: یک مساله یادگیری هنگامی قوانین انجمنی محسوب میشود که هدف کشف کردن قواعدی باشد که بخش بزرگی از دادهها را توصیف میکنند. مثلا، «شخصی که کالای الف را خریداری کند، تمایل به خرید کالای ب نیز دارد».
خوشهبندی: یک مساله هنگامی خوشهبندی محسوب میشود که قصد کشف گروههای ذاتی (دادههایی که ذاتا در یک گروه خاص میگنجند) در دادهها وجود داشته باشد. مثلا، گروهبندی مشتریان بر اساس رفتار خرید آنها.
یادگیری تقویتی
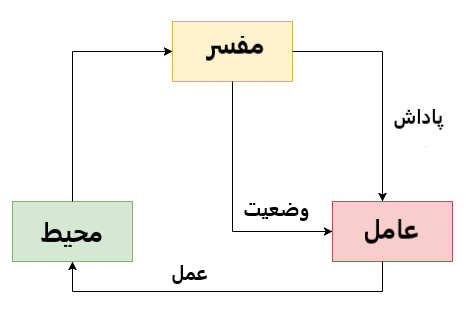
یک برنامه رایانهای که با محیط پویا در تعامل است باید به هدف خاصی دستیابد (مانند بازی کردن با یک رقیب یا راندن خودرو). این برنامه بازخوردهایی را با عنوان پاداشها و تنبیهها فراهم و فضای مساله خود را بر همین اساس هدایت میکند. با استفاده از یادگیری تقویتی، ماشین میآموزد که تصمیمات مشخصی را در محیطی که دائم در معرض آزمون و خطا است اتخاذ کند.
مثال:
ریاضیات هوشمندی
نظریه یادگیری ماشین، زمینهای است که در آن آمار و احتمال، علوم رایانه و مباحث الگوریتمی – بر مبنای یادگیری تکرار شونده – کاربرد دارد و میتواند برای ساخت نرمافزارهای کاربردی هوشمند مورد استفادده قرار بگیرد.
چرا نگرانی از ریاضیات؟
دلایل متعددی وجود دارد که آموختن ریاضیات برای یادگیری ماشین را الزامی میکند. برخی از این دلایل در ادامه آورده شدهاند.
انتخاب الگوریتم مناسب برای یک مساله خاص، که شامل در نظر گرفتن صحت، زمان آموزش، پیچیدگی مدل، تعداد پارامترها و تعداد مشخصهها است.
استفاده از موازنه واریانس-بایاس برای شناسایی حالاتی که بیشبرازش با کمبرازش در آنها به وقوع پیوسته است.
انتخاب تنظیمات پارامترها و استراتژیهای اعتبارسنجی.
تخمین دوره تصمیمگیری صحیح و عدم قطعیت.
چه سطحی از ریاضیات مورد نیاز است؟
پرسشی که برای اغلب افراد علاقمند به آموختن علم یادگیری ماشین مطرح است و بارها در مقالات و کنفرانسهای گوناگون این حوزه به آن پاسخ داده شده این است که چه میزان تسلط بر ریاضیات برای درک این علم مورد نیاز محسوب میشود. پاسخ این پرسش چند بُعدی و وابسته به سطح دانش ریاضی هر فرد و میزان علاقمندی آن شخص به یادگیری است. در ادامه حداقل دانش ریاضی که برای مهندسان یادگیری ماشین و تحلیلگران داده مورد نیاز است آورده شده.
جبر خطی: ماتریسها و عملیات روی آنها، پروجکشن، اتحاد و تجزیه، ماتریسهای متقارن، متعامدسازی.
نظریه آمار و احتمالات: قوانین احتمال و اصل (منطق)، نظریه بیزی، متغیرهای تصادفی، واریانس و امید ریاضی، توزیعهای توام و شرطی، توزیع استاندارد.
حساب: حساب دیفرانسیل و انتگرال، مشتقات جزئی.
الگوریتمها و بهینهسازی پیچیدگیها: درختهای دودویی، هیپ، استک