شبکههای عصبی مصنوعی

پیدایش شبکههای عصبی مصنوعی
مغر انسان، به اذعان بسیاری از دانشمندان، پیچیدهترین سیستمی است که تا کنون در کل گیتی مشاهده شده و مورد مطالعه قرار گرفته است. اما این سیستم پیچیده نه ابعادی در حد کهشکشان دارد و نه تعداد اجزای سازندهاش، بیشتر از پردازندههای ابررایانههای امروزی است. پیچیدگی راز آلود این سیستم بی نظیر، به اتصالهای فراوان موجود میان اجزای آن بازمیگردد. این همان چیزی است که مغز ۱۴۰۰ گرمی انسان را از همه سیستمهای دیگر متمایز می کند.
فرایندهای خودآگاه و ناخودآگاهی که در حدود جغرافیایی بدن انسان رخ میدهند، همگی تحت مدیریت مغز هستند. برخی از این فرایندها آنقدر پیچیده هستند، که هیچ رایانه یا ابررایانهای در جهان امکان پردازش و انجام آن را ندارد. با این حال، تحقیقات نشان میدهند که واحدهای سازنده مغز انسان، از نظر سرعت عملکرد، حدود یک میلیون بار کندتر از ترانزیستورهای مورد استفاده در تراشههای سیلیکونی CPU رایانه هستند.
سرعت و قدرت پردازش بسیار بالای مغز انسان، به ارتباطهای بسیار انبوهی باز میگردد که در میان سلولهای سازنده مغز وجود دارد و اساساً، بدون وجود این لینکهای ارتباطی، مغز انسان هم به یک سیستم معمولی کاهش مییافت و قطعاً امکانات فعلی را نداشت.
گذشته از همه اینها، عملکرد عالی مغز در حل انواع مسائل و کارایی بالای آن، باعث شده است تا شبیه سازی مغز و قابلیتهای آن به مهمترین آرمان معماران سختافزار و نرمافزار تبدیل شود. در واقع اگر روزی فرا برسد (که البته ظاهرا خیلی هم دور نیست) که بتوانیم رایانهای در حد و اندازههای مغز انسان بسازیم، قطعاً یک انقلاب بزرگ در علم، صنعت و البته زندگی انسانها، رخ خواهد داد.
از چند دهه گذشته که رایانهها امکان پیادهسازی الگوریتمهای محاسباتی را فراهم ساختهاند، در راستای شبیهسازی رفتار محاسباتی مغز انسان، کارهای پژوهشی بسیاری از سوی متخصصین علوم رایانه، مهندسین و همچنین ریاضیدانها شروع شده است، که نتایج کار آنها، در شاخهای از علم هوش مصنوعی و در زیرشاخه هوش محاسباتی تحت عنوان موضوع «شبکههای عصبی مصنوعی» یا Artificial Neural Networks (به اختصار: ANNs) طبقهبندی شده است. در مبحث شبکههای عصبی مصنوعی، مدلهای ریاضی و نرمافزاری متعددی با الهام گرفتن از مغز انسان پیشنهاد شدهاند، که برای حل گستره وسیعی از مسائل علمی، مهندسی و کاربردی، در حوزه های مختلف کاربرد دارند.
کاربردهای شبکههای عصبی مصنوعی
امروز به قدری استفاده از سیستمهای هوشمند و به ویژه شبکه عصبی مصنوعی گسترده شده است که میتوان این ابزارها را در ردیف عملیات پایه ریاضی و به عنوان ابزارهای عمومی و مشترک، طبقهبندی کرد. چرا که کمتر رشته دانشگاهی است که نیازی به تحلیل، تصمیمگیری، تخمین، پیشبینی، طراحی و ساخت داشته باشد و در آن از موضوع شبکههای عصبی استفاده نشده باشد. فهرستی که در ادامه آمده است، یک فهرست نه چندان کامل است. اما همین فهرست مختصر نیز گستردگی کاربردهای شبکههای عصبی مصنوعی را تا حدود زیادی به تصویر میکشد.
| زمینه کلی | کاربرد |
| علوم کامپیوتر | طبقهبندی اسناد و اطلاعات در شبکههای کامپیوتری و اینترنتتوسعه نرمافزارهای نظارتی و نرمافزارهای آنتیویروس |
| علوم فنی و مهندسی | مهندسی معکوس و مدلسازی سیستمهاپیشبینی مصرف بار الکتریکیعیبیابی سیستمهای صنعتی و فنیطراحی انواع سیستمهای کنترلطراحی و بهینهسازی سیستمهای فنی و مهندسیتصمیمگیری بهینه در پروژههای مهندسی |
| علوم پایه و نجوم | پیشبینی نتایج آزمایشهاارزیابی و تخمین صحت فرضیهها و نظریههامدلسازی پدیدههای فیزیکی پیچیده |
| علوم پزشکی | مدلسازی فرایندهای زیست-پزشکیتشخیص بیماریها با توجه به نتایج آزمایش پزشکی و تصویربرداریپیشبینی نتایج درمان و عمل جراحیپیادهسازی ادوات و الگوهای درمانی اختصاصی بیمار |
| علوم تجربی و زیستی | مدلسازی و پیشبینی پدیدههای زیستی و محیطیپیشبینی سریهای زمانی با کاربرد در علوم زیست-محیطیطبقهبندی یافتههای ناشی از مشاهدات تجربیشناسایی الگوهای مخفی و تکرار شونده در طبیعت |
| علوم اقتصادی و مالی | پیشبینی قیمت سهام و شاخص بورسطبقهبندی علائم و نمادهای بورستحلیل و ارزیابی ریسکتخصیص سرمایه و اعتبار |
| علوم اجتماعی و روانشناسی | طبقهبندی و خوشهبندی افراد و گروههامدلسازی و پیشبینی رفتارهای فردی و اجتماعی |
| هنر و ادبیات | پیشبینی موفقیت و مقبولیت عمومی آثار هنریاستخراج مولفههای اساسی از متون ادبی و آثار هنریطبقهبندی و کاوش متون ادبی |
| علوم نظامی | هدفگیری و تعقیب در سلاحهای موشکیپیادهسازی سیستمهای دفاعی و پدافند هوشمندپیشبینی رفتار نیروی مهاجم و دشمنپیادهسازی حملات و سیستمهای دفاعی در جنگ الکترونیک (جنگال) |
انواع شبکههای عصبی مصنوعی
انواع مختلفی از مدلهای محاسباتی تحت عنوان کلی شبکههای عصبی مصنوعی معرفی شدهاند که هر یک برای دستهای از کاربردها قابل استفاده هستند و در هر کدام از وجه مشخصی از قابلیتها و خصوصیات مغز انسان الهام گرفته شده است.
در همه این مدلها، یک ساختار ریاضی در نظر گرفته شده است که البته به صورت گرافیکی هم قابل نمایش دادن است و یک سری پارامترها و پیچهای تنظیم دارد. این ساختار کلی، توسط یک الگوریتم یادگیری یا تربیت (Training Algorithm) آن قدر تنظیم و بهینه میشود، که بتواند رفتار مناسبی را از خود نشان دهد.https://beta.kaprila.com/a/templates_ver2/templates.php?ref=blog.faradars&id=string-1&w=760&h=140&t=string&bg=fffff3&hover=ffffcb&rows=3&cid=200,42,33&wr=score_2,cat_2_neural_network,cat_low_neural_network
نگاهی به فرایند یادگیری در مغز انسان نیز نشان میدهد که در واقع ما نیز در مغزمان فرایندی مشابه را تجربه میکنیم و همه مهارتها، دانستهها و خاطرات ما، در اثر تضعیف یا تقویت ارتباط میان سلولهای عصبی مغز شکل میگیرند. این تقویت و تضعیف در زبان ریاضی، خود را به صورت تنظیم یک پارامتر (موسوم به وزن یا Weight) مدلسازی و توصیف میکند.
اما طرز نگاه مدلهای مختلف شبکههای عصبی مصنوعی کاملا متفاوت است و هر یک، تنها بخشی از قابلیتهای یادگیری و تطبیق مغز انسان را هدف قرار داده و تقلید کردهاند. در ادامه به مرور انواع مختلف شبکههای عصبی پرداختهایم که مطالعه آن در ایجاد یک آشنایی اولیه بسیار موثر خواهد بود.
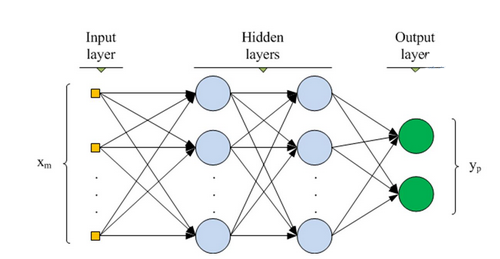
پرسپترون چندلایه یا MLP
یکی از پایهایترین مدلهای عصبی موجود، مدل پرسپترون چند لایه یا Multi-Layer Perceptron (به اختصار MLP) است که عملکرد انتقالی مغز انسان را شبیهسازی میکند. در این نوع شبکه عصبی، بیشتر رفتار شبکهای مغز انسان و انتشار سیگنال در آن مد نظر بوده است و از این رو، گهگاه با نام شبکههای پیشخورد (Feedforward Networks) نیز خوانده میشوند. هر یک از سلولهای عصبی مغز انسان، موسوم به نورون (Neuron)، پس از دریافت ورودی (از یک سلول عصبی یا غیر عصبی دیگر)، پردازشی روی آن انجام میدهند و نتیجه را به یک سلول دیگر (عصبی یا غیر عصبی) انتقال میدهند. این رفتار تا حصول نتیجهای مشخص ادامه دارد، که احتمالاً در نهایت منجر به یک تصمیم، پردازش، تفکر و یا حرکت خواهد شد.
- مطلب پیشنهادی برای مطالعه: پرسپترون چند لایه در پایتون — راهنمای کاربردی
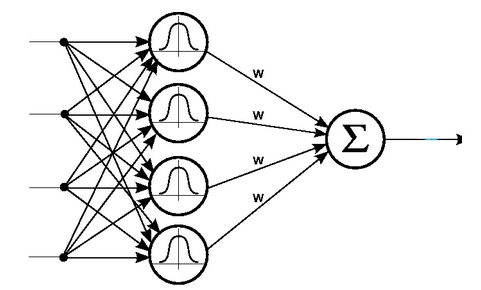
شبکههای عصبی شعاعی یا RBF
مشابه الگوی شبکههای عصبی MLP، نوع دیگری از شبکههای عصبی وجود دارند که در آنها، واحدهای پردازنده، از نظر پردازشی بر موقعیت خاصی متمرکز هستند. این تمرکز، از طریق توابع شعاعی یا Radial Basis Functions (به اختصار RBF) مدلسازی میشود. از نظر ساختار کلی، شبکههای عصبی RBF تفاوت چندانی با شبکههای MLP ندارند و صرفا نوع پردازشی که نورونها روی ورودهایشان انجام میدهند، متفاوت است. با این حال، شبکههای RBF غالبا دارای فرایند یادگیری و آمادهسازی سریعتری هستند. در واقع، به دلیل تمرکز نورونها بر محدوده عملکردی خاص، کار تنظیم آنها، راحتتر خواهد بود.
- مطلب پیشنهادی برای مطالعه: شبکه عصبی در متلب — از صفر تا صد
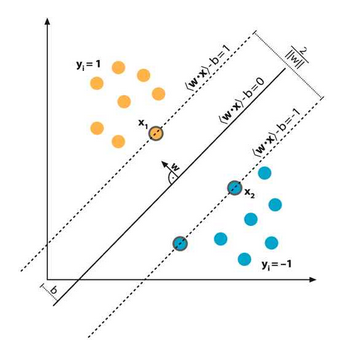
ماشینهای بردار پشتیبان یا SVM
در شبکههای عصبی MLP و RBF، غالبا توجه بر بهبود ساختار شبکه عصبی است، به نحوی که خطای تخمین و میزان اشتباههای شبکه عصبی کمینه شود. اما در نوع خاصی از شبکه عصبی، موسوم به ماشین بردار پشتیبان یا Support Vector Machine (به اختصار SVM)، صرفا بر روی کاهش ریسک عملیاتی مربوط به عدم عملکرد صحیح، تمرکز میشود. ساختار یک شبکه SVM، اشتراکات زیادی با شبکه عصبی MLP دارد و تفاوت اصلی آن عملاً در شیوه یادگیری است.
- مطالب پیشنهادی برای مطالعه:
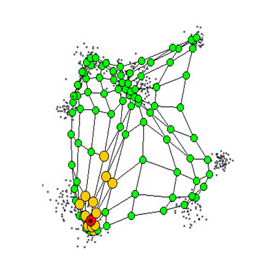
نگاشتهای خودسازمانده یا SOM
شبکه عصبی کوهونن (Kohonen) یا نگاشت خودسازمانده و یا Self-Organizing Map (به اختصار SOM) نوع خاصی از شبکه عصبی است که از نظر شیوه عملکرد، ساختار و کاربرد، کاملاً با انواع شبکه عصبی که پیش از این مورد بررسی قرار گرفتند، متفاوت است. ایده اصلی نگاشت خودسازمانده، از تقسیم عملکردی ناحیه قشری مغز، الهام گرفته شده است و کاربرد اصلی آن در حل مسائلی است که به مسائل «یادگیری غیر نظارت شده» معروف هستند. در واقع کارکرد اصلی یک SOM، در پیدا کردن شباهتها و دستههای مشابه در میان انبوهی از دادههایی است که در اختیار آن قرار گرفته است. این وضعیت مشابه کاری است که قشر مغز انسان انجام میدهد و انبوهی از ورودیهای حسی و حرکتی به مغز را در گروههای مشابهی طبقهبندی (یا بهتر است بگوییم خوشهبندی) کرده است.
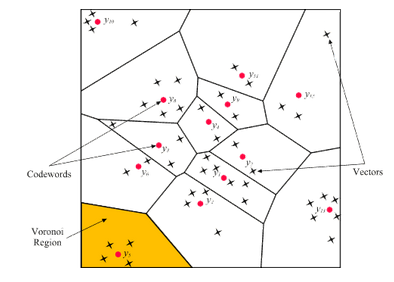
- مطالب پیشنهادی برای مطالعه: انواع سلول ها و لایه ها در شبکه های عصبی — راهنمای جامع
یادگیرنده رقمیساز بردار یا LVQ
این نوع خاص شبکه عصبی، تعمیم ایده شبکههای عصبی SOM برای حل مسائل یادگیری نظارت شده است. از طرفی شبکه عصبی LVQ (یا Learning Vector Quantization)، میتواند به این صورت تعبیر شود که گویا شبکه عصبی MLP با یک رویکرد متفاوت، کاری را که باید انجام بدهد یاد میگیرد. اصلیترین کاربرد این نوع شبکه عصبی در حل مسائل طبقهبندی است که گستره وسیعی از کاربردهای سیستمهای هوشمند را پوشش میدهد.
شبکه عصبی هاپفیلد یا Hopfield
این نوع شبکه عصبی، بیشتر دارای ماهیتی شبیه به یک سیستم دینامیکی است که دو یا چند نقطه تعادل پایدار دارد. این سیستم با شروع از هر شرایط اولیه، نهایتا به یکی از نقاط تعادلش همگرا میشود. همگرایی به هر نقطه تعادل، به عنوان تشخیصی است که شبکه عصبی آن را ایجاد کرده است و در واقع میتواند به عنوان یک رویکرد برای حل مسائل طبقهبندی استفاده شود. این سیستم، یکی از قدیمیترین انواع شبکههای عصبی است که دارای ساختار بازگشتی است و در ساختار آن فیدبکهای داخلی وجود دارند.
خانواده «شبکههای عصبی مصنوعی» (Artificial Neural Networks) هر روز شاهد حضور اعضای جدیدی است. با توجه به تعدد انواع شبکه های عصبی موجود، در این مطلب، یک راهنمای جامع از انواع شبکه های عصبی مصنوعی ارائه شده است. در این راهنما، توپولوژی انواع شبکه های عصبی مصنوعی روش عملکرد و کاربرد شبکههای عصبی مصنوعی مورد بررسی قرار گرفته است. برای آشنایی با مفهوم شبکههای عصبی مصنوعی و پیادهسازی آن در زبانهای برنامهنویسی گوناگون، مطالعه مطالب زیر پیشنهاد میشود.
فهرست مطالب این نوشته
- شبکههای عصبی مصنوعی – از صفر تا صد
- ساخت شبکه عصبی — راهنمای مقدماتی
- شبکه عصبی در متلب — از صفر تا صد
- ساخت شبکه عصبی (Neural Network) در پایتون — به زبان ساده
- شبکه عصبی مصنوعی و پیادهسازی در پایتون — راهنمای کاربردی
- کدنویسی شبکههای عصبی مصنوعی چند لایه در پایتون — راهنمای کامل
- شبکههای عصبی در پایتون و R – درک و کد نویسی از صفر تا صد
- ساخت شبکه های عصبی در نرم افزار R
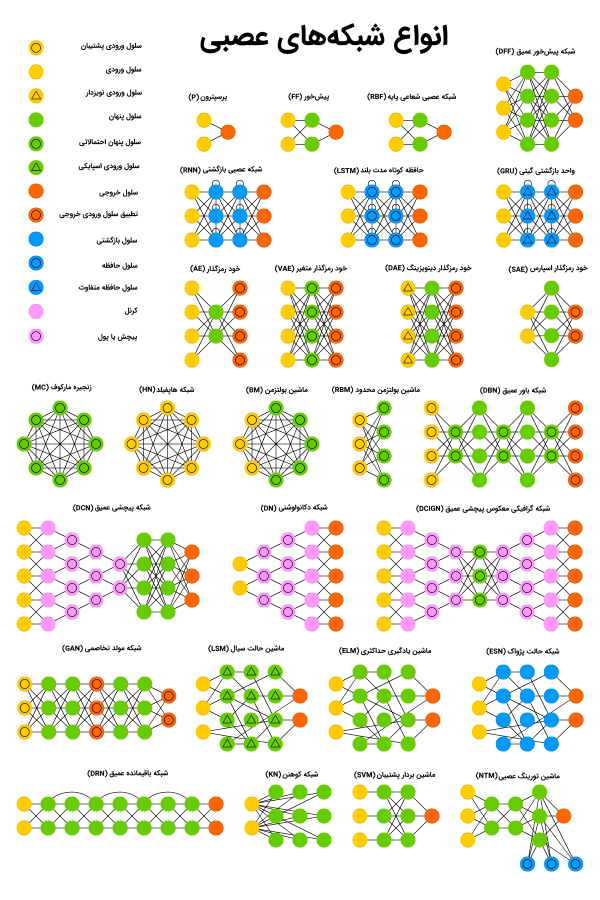
انواع شبکههای عصبی مصنوعی
در ادامه، ۲۷ مورد از انواع شبکه های عصبی مصنوعی، معرفی شده است. در تصویر زیر، راهنمای جامع انواع شبکههای عصبی ارائه شده است. برای مشاهده این راهنمای جامع در ابعاد بزرگ، کلیک کنید.
{kind=link}
{kind=link}
برای مشاهده تصویر بالا، در ابعاد بزرگ، کلیک کنید.
شبکه عصبی پرسپترون
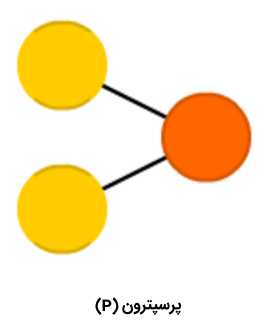
«پرسپترون» (Perceptron | P)، سادهترین و قدیمیترین مدل از نورون محسوب میشود که تاکنون توسط بشر شناخته شده است. پرسپترون، تعدادی ورودی را دریافت، آنها را تجمیع و تابع فعالسازی را روی آنها اعمال میکند و در نهایت، آنها را به لایه خروجی پاس میدهد. در این قسمت، معجزه اصلی شبکههای عصبی مصنوعی به وقوع نمیپیوندد. برای مطالعه بیشتر پیرامون پرسپترون چند لایه، مطالعه مطلب «پرسپترون چند لایه در پایتون — راهنمای کاربردی» پیشنهاد میشود.
شبکه عصبی پیشخور
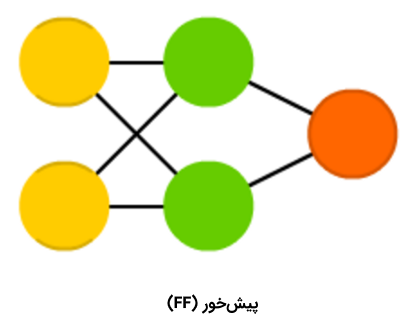
«شبکههای عصبی پیشخور» (Feed Forward Neural Networks | FF) نیز از اعضای قدیمی خانواده شبکههای عصبی محسوب میشوند و رویکرد مربوط به آنها از دهه ۵۰ میلادی نشأت میگیرد. عملکرد این الگوریتم، به طور کلی از قواعد زیر پیروی میکند:
- همه گرهها کاملا متصل هستند.
- فعالسازی از لایه ورودی به خروجی، بدون داشتن حلقه رو به عقب، جریان پیدا میکند.
- یک لایه (لایه پنهان) بین ورودی و خروجی وجود دارد.
در اغلب مواقع، این نوع از شبکههای عصبی با استفاده از روش «پسانتشار» (Backpropagation) آموزش داده میشوند.
شبکه عصبی شعاعی پایه
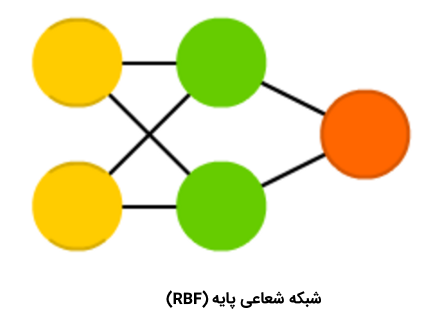
«شبکههای عصبی شعاعی پایه» (Radial Basis Networks | RBF) در واقع شبکههای عصبی پیشخوری (FF) هستند که از «تابع شعاعی پایه» (Radial Basis Function)، به جای «تابع لجستیک» (Logistic Function)، به عنوان تابع فعالسازی استفاده میکنند. سوالی که در این وهله مطرح میشود این است که تفاوت شبکه عصبی شعاعی پایه با شبکه عصبی پیشخور چیست؟ تابع لجستیک برخی از مقادیر دلخواه را به یک بازه ۰ تا ۱ نگاشت میکند تا به یک پرسش «بله یا خیر» (پرسش دودویی) پاسخ دهد. این نوع از شبکههای عصبی برای «دستهبندی» (Classification) و «سیستمهای تصمیمگیری» (Decision Making Systems) مناسب هستند، ولی برای مقادیر پیوسته عملکرد بدی دارند.
این در حالی است که توابع شعاعی پایه به این پرسش پاسخ میدهند که «چقدر از هدف دوریم؟» و این امر موجب میشود تا این شبکههای عصبی برای تخمین تابع و کنترل ماشین (برای مثال، به عنوان جایگزینی برای کنترل کننده PID) مناسب محسوب شوند. به طور خلاصه باید گفت که شبکههای عصبی شعاعی پایه در واقع نوعی از شبکههای عصبی پیشخور با تابع فعالسازی و ویژگیهای متفاوت هستند.
شبکه عصبی پیشخور عمیق
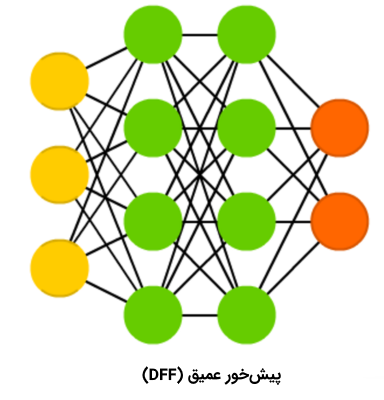
«شبکه عصبی پیشخور عمیق» (Deep Feed Forward Neural Networks | DFF)، در اوایل دهه ۹۰ میلادی، مقدمهای بر بحث شبکههای عصبی شد. این نوع از شبکههای عصبی نیز شبکههای عصبی پیشخور هستند، ولی بیش از یک «لایه پنهان» (Hidden Layer) دارند. سوالی که در این وهله پیش میآید آن است که تفاوت این نوع از شبکههای عصبی با شبکههای عصبی پیشخور سنتی در چیست؟
در هنگام آموزش دادن یک شبکه عصبی پیشخور، تنها بخش کوچکی از خطا به لایه پیشین پاس داده میشود. به همین دلیل، استفاده از لایههای بیشتر، منجر به رشد نمایی زمان آموزش میشود و همین موضوع، موجب میشود که شبکههای عصبی پیشخور عمیق، عملا بدون کاربرد و غیر عملی باشند. در اوایل سال دو هزار میلادی، رویکردهایی توسعه پیدا کردند که امکان آموزش دادن یک شبکه عصبی پیشخور عمیق (DFF) را به صورت موثر فراهم میکردند. امروزه، این شبکههای عصبی، هسته سیستمهای یادگیری ماشین مدرن را تشکیل میدهند و هدفی مشابه با هدف شبکههای عصبی پیشخور (FF) را پوشش میدهند؛ اما نتایج بهتری را دربردارند.
شبکههای عصبی بازگشتی
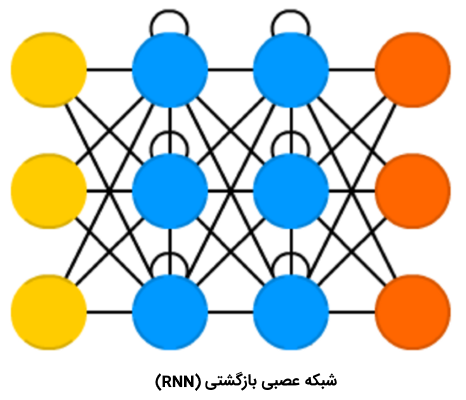
«شبکههای عصبی بازگشتی» (Recurrent Neural Networks | RNN) نوع متفاوتی از سلولها با عنوان «سلولهای بازگشتی» (Recurrent Cells) را معرفی میکنند. اولین شبکه از این نوع، «شبکه جردن» (Jordan Network) است؛ در این نوع از شبکه، هر یک از سلولهای پنهان، خروجی خود را با تاخیر ثابت – یک یا تعداد بیشتری تکرار- دریافت میکنند. صرف نظر از این موضوع، شبکه جردن مشابه با شبکههای عصبی پیشخور متداول بود.https://beta.kaprila.com/a/templates_ver2/templates.php?ref=blog.faradars&id=string-1&w=760&h=140&t=string&bg=fffff3&hover=ffffcb&rows=3&cid=2021,33,1651&wr=score,score,score_3
البته، تغییرات گوناگونی مانند پاس دادن حالت به «گرههای ورودی» (Input Nodes)، تأخیر متغیرها و دیگر موارد در این نوع از شبکهها اتفاق افتاده، اما ایده اصلی به همان صورت باقی مانده است. این نوع از شبکههای عصبی (NN) اساسا هنگامی استفاده میشوند که «زمینه» (Context) مهم است و در واقع یعنی هنگامی که تصمیمگیریها از تکرارهای قبلی یا نمونهها، میتواند نمونههای کنونی را تحت تاثیر قرار دهد. به عنوان مثالی متداول از این نوع از زمینهها، میتوان به «متن» (Text) اشاره کرد. در متن، یک کلمه را میتوان تنها در زمینه کلمه یا جمله پیشین تحلیل کرد.
حافظه کوتاه مدت بلند
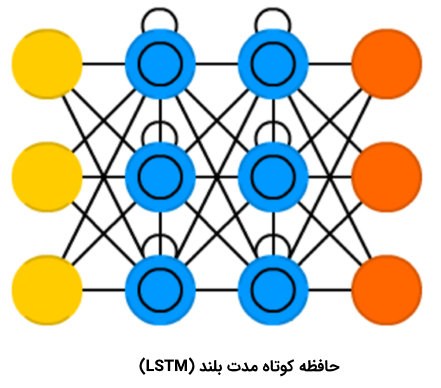
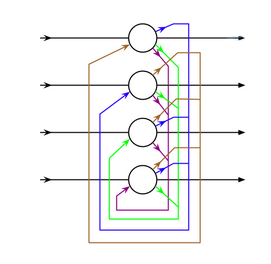
«حافظه کوتاه مدت بلند» (Long/Short Term Memory | LSTM) نوع جدیدی از «سلول حافظه» (Memory Cell) را معرفی میکند. این سلول میتواند دادهها را هنگامی که دارای شکاف زمانی (یا تاخیر زمانی) هستند، پردازش کند. شبکه عصبی پیشخور میتواند متن را با «به خاطر سپردن» ده کلمه پیشین پردازش کند. این در حالی است که LSTM میتواند قابهای ویدئو را با «به خاطر سپردن» چیزی که در قابهای بسیار پیشین اتفاق افتاده است پردازش کند. شبکههای LSTM به طور گستردهای برای «بازشناسی گفتار» (Speech Recognition) و «بازشناسی نوشتار» (Writing Recognition) مورد استفاده قرار میگیرند. سلولهای حافظه اساسا ترکیبی از یک جفت عنصر که به آنها گیت گفته میشود هستند. این عنصرها، بازگشتی هستند و چگونگی به یاد آوردن و فراموش کردن اطلاعات را کنترل میکنند. ساختار این نوع از شبکهها، در تصویر زیر به خوبی مشخص است. این نکته که هیچ تابع فعالسازی بین بلوکها وجود ندارد نیز شایان توجه است.
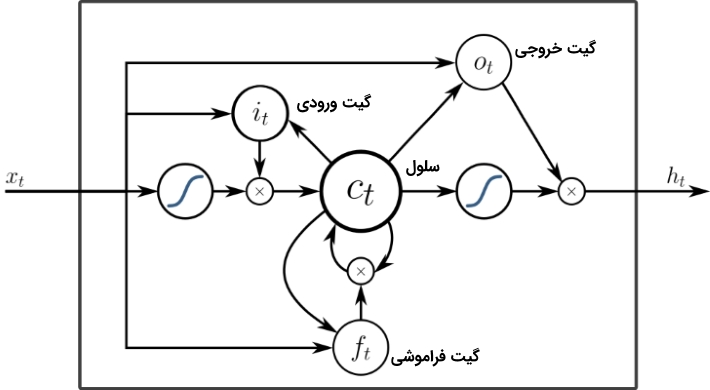
Xهای موجود در نمودار، گیتها هستند و وزن و گاهی تابع فعالسازی خود را دارند. برای هر نمونه، Xها تصمیم میگیرند دادهها را به جلو پاس دهند یا خیر، حافظه را پاک کنند یا نه و به همین ترتیب. گیت ورودی، تصمیم میگیرد که چه میزان اطلاعات از آخرین نمونه در حافظه نگهداری میشود. گیت خروجی میزان دادههای پاس داده شده به لایه بعدی را تنظیم میکند و گیت فراموشی، نرخ خارج شدن از موارد ذخیره شده در حافظه را کنترل میکند. آنچه بیان شد، یک شکل بسیار ساده از سلولهای LSTM است و معماریهای متعدد دیگری نیز برای این نوع از شبکههای عصبی، موجود است.
شبکه عصبی واحد بازگشتی گِیتی
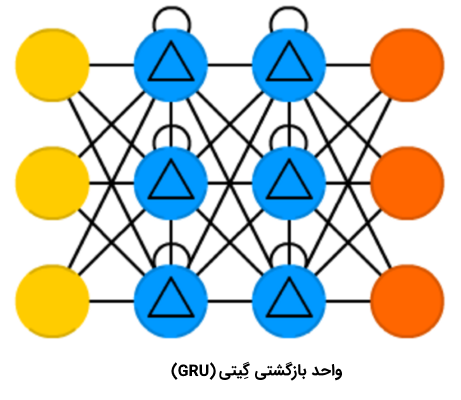
«واحد بازگشتی گیتی» (Gated Recurrent Unit | GRU) نوعی از LSTM با گیتها و دوره زمانی متفاوت است. این نوع از شبکه عصبی ساده به نظر میآید. در حقیقت، فقدان گیت خروجی، تکرار چندین باره یک خروجی مشابه را برای ورودیها سادهتر میسازد. این نوع از شبکههای عصبی بازگشتی در حال حاضر بیشتر در «موتور متن به گفتار» (Speech Synthesis) و «ترکیب صدا» (Music Synthesis) به کار میرود. البته، ترکیب واقعی LSTM با GRU اندکی متفاوت است. زیرا، همه گیتهای LSTM در یک گیت که به آن گیت به روز رسانی گفته میشود ترکیب شدهاند و گیت «بازشناسی» (Reset) از نزدیک به ورودی گره خورده است. GRUها نسبت به LSTMها کمتر از منابع استفاده میکنند و اثر مشابهی را دارند.
شبکه عصبی خود رمزگذار
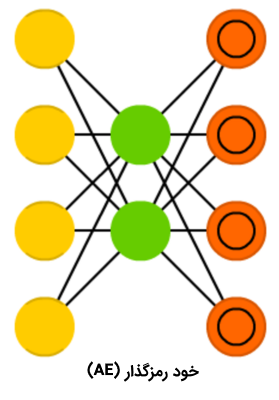
شبکههای عصبی «خود رمزگذار» (Auto Encoder | AE) برای دستهبندی، «خوشهبندی» (Clustering) و «فشردهسازی ویژگیها» (Feature Compression) استفاده میشوند. هنگامی که یک شبکه عصبی پیشخور برای دستهبندی آموزش داده میشود، باید نمونههای X در Y دسته به عنوان خوراک داده شوند و انتظار میرود یکی از سلولهای Y فعالسازی شده باشد. به این مورد، «یادگیری نظارت شده» (Supervised Learning) گفته میشود. از سوی دیگر، شبکههای عصبی خود رمزگذار را میتوان بدون نظارت، آموزش داد. با توجه به ساختار این شبکهها (که در آن تعداد لایههای پنهان کوچکتر از تعداد سلولهای ورودی است و تعداد سلولهای خروجی برابر با سلولهای ورودی است) و اینکه AE به نوعی آموزش داده میشود که خروجی تا حد امکان به ورودی نزدیک باشد، شبکه عصبی خود رمزگذار مجبور میشود دادهها را تعمیم دهد و به دنبال الگوهای متداول بگردد.
شبکه عصبی خود رمزگذار متغیر
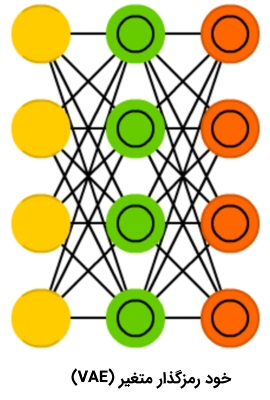
«شبکه عصبی خود رمزگذار متغیر» (Variational Auto Encoder | VAE) در مقایسه با شبکه عصبی خود رمزگذار، احتمالات را به جای ویژگیها فشرده میکند. علارغم تغییرات کوچک که بین دو شبکه عصبی مذکور اتفاق افتاده است، هر یک از این انواع شبکه های عصبی مصنوعی به پرسش متفاوتی پاسخ میدهند. شبکه عصبی خودرمزگذار به پرسش «چگونه میتوان دادهها را تعمیم داد؟» پاسخ میدهد، در حالی که شبکه عصبی خود رمزگذار متغیر به پرسش «اتصال بین دو رویداد چقدر قوی است؟ آیا باید خطا را بین دو رویداد توزیع کرد یا آنها به طور کامل مستقل هستند؟» پاسخ میدهد.
شبکه عصبی خود رمزگذار دینوزینگ
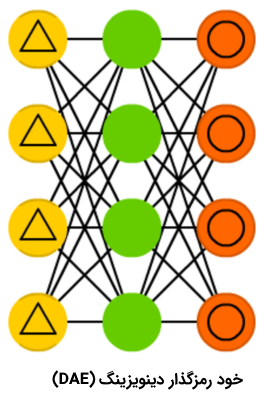
با وجود جالب بودن شبکههای خود رمزگذار، اما این شبکههای عصبی گاهی به جای پیدا کردن مستحکمترین ویژگی، فقط با دادههای ورودی سازگار میشوند (این مورد مثالی از بیشبرازش یا همان Overfitting است). شبکه عصبی «خود رمزگذار دینوزینگ» (Denoising AutoEncoder | DAE) اندکی نویز به سلول ورودی اضافه میکنند. با این کار، شبکه عصبی خود رمزگذار دینوزینگ، مجبور میشود که خروجی را از یک ورودی نویزی، مجددا بسازد و آن را عمومیتر کند و ویژگیهای متداول بیشتری را انتخاب کند.