در علم یادگیری ماشین (Machine Learning)، به موضوع طراحی ماشینهایی پرداخته میشود که با استفاده از مثالهای داده شده به آنها و تجربیات خودشان، بیاموزند. در واقع، در این علم تلاش میشود تا با بهرهگیری از الگوریتمها، یک ماشین به شکلی طراحی شود که بدون آنکه صراحتا برنامهریزی و تک تک اقدامات به آن دیکته شود بتواند بیاموزد و عمل کند. در یادگیری ماشین، به جای برنامهنویسی همه چیز، دادهها به یک الگوریتم عمومی داده میشوند و این الگوریتم است که براساس دادههایی که به آن داده شده منطق خود را میسازد. یادگیری ماشین روشهای گوناگونی دارد که از آن جمله میتوان به یادگیری نظارت شده، نظارت نشده و یادگیری تقویتی اشاره کرد. الگوریتمهای مورد استفاده در یادگیری ماشین جزو این سه دسته هستند.
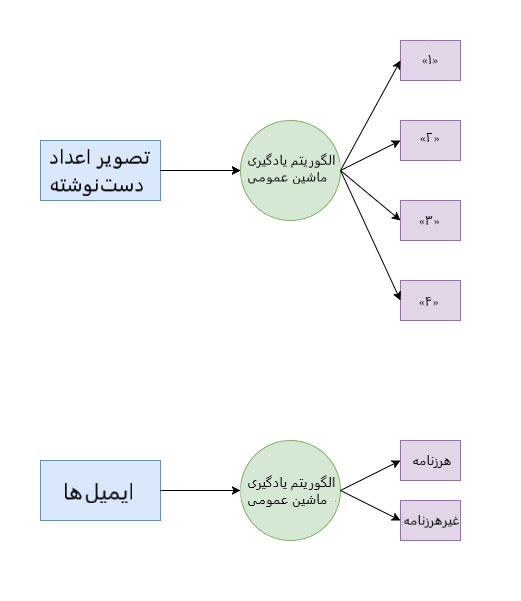
الگوریتم دستهبندی مثالی برای مطلب بیان شده است. این الگوریتم میتواند دادهها را در گروههای (دستههای) مختلف قرار دهد. الگوریتم دستهبندی که برای بازشناسی الفبای دستخط استفاده میشود را میتوان برای دستهبندی ایمیلها به هرزنامه و غیر هرزنامه نیز استفاده کرد.
تام میشل (Tom M. Mitchell) در تعریف یادگیری ماشین میگوید: «(یک برنامه یادگیرنده) برنامه رایانهای است که به آن گفته شده تا از تجربه E مطابق با برخی وظایف T، و کارایی عملکرد P برای وظیفه T که توسط P سنجیده میشود، یاد بگیرد که تجربه E را بهبود ببخشد.»
به عنوان مثالی دیگر، میتوان بازی دوز (چکرز) را فرض کرد.
E: تجربه بازی کردن بازی دوز به دفعات زیاد است.
T: وظیفه انجام بازی دوز است.
P: احتمال آنکه برنامه بتواند بازی بعدی را ببرد است.
مثالهایی از یادگیری ماشین
مثالهای متعددی برای یادگیری ماشین وجود دارند. در اینجا چند مثال از مسائل طبقهبندی زده میشود که در آنها هدف دستهبندی اشیا به مجموعهای مشخص از گروهها است.
تشخیص چهره: شناسایی چهره در یک تصویر (یا تشخیص اینکه آیا چهرهای وجود دارد یا خیر).
فیلتر کردن ایمیلها: دستهبندی ایمیلها در دو دسته هرزنامه و غیر هرزنامه.
تشخیص پزشکی: تشخیص اینکه آیا بیمار مبتلا به یک بیماری است یا خیر.
پیشبینی آب و هوا: پیشبینی اینکه برای مثال فردا باران میبارد یا خیر.
نیازهای یادگیری ماشین
یادگیری ماشین زمینه مطالعاتی است که از هوش مصنوعی سر بر آورده. بشر با استفاده از هوش مصنوعی بهدنبال ساخت ماشینهای بهتر و هوشمند است. اما پژوهشگران در ابتدا به جز چند وظیفه ساده، مانند یافتن کوتاهترین مسیر بین نقطه A و B، در برنامهریزی ماشینها برای انجام وظایف پیچیدهتری که بهطور مداوم با چالش همراه هستند ناتوان بودند. بر همین اساس، ادراکی مبنی بر این شکل گرفت که تنها راه ممکن برای تحقق بخشیدن این مهم، طراحی ماشینهایی است که بتوانند از خودشان یاد بگیرند. ماشین در این رویکرد به مثابه کودکی است که از خودش میآموزد. بنابراین، یادگیری ماشین بهعنوان یک توانایی جدید برای رایانهها مطرح شد. امروزه این علم در بخشهای گوناگون فناوری مورد استفاده قرار میگیرد، و بهرهگیری از آن به اندازهای زیاد شده که افراد اغلب از وجودش در ابزارها و لوازم روزمره خود بیخبرند.
یافتن الگوها در دادههای موجود در سیاره زمین، تنها برای مغز انسان امکانپذیر است. اما هنگامی که حجم دادهها بسیار زیاد میشود و زمان لازم برای انجام محاسبات افزایش مییابد، نیاز به یادگیری ماشین به عنوان علمی مطرح میشود که به افراد در کار با دادههای انبوه در حداقل زمان کمک میکند.
با وجود آنکه مباحث مِهداده (کلان داده/big data) و پردازش ابری به دلیل کاربردی که در جنبههای گوناگون زندگی بشر دارند حائز اهمیت شدهاند، اما در حقیقت یادگیری ماشین فناوری است که به دانشمندان داده در تحلیل بخشهای بزرگ داده، خودکارسازی فرآیندها، بازشناسی الگوها و ارزشآفرینی کمک میکند.
روشی که اکنون برای دادهکاوی استفاده میشود برای سالها مطرح بوده، اما موثر واقع نشده زیرا قدرت رقابتی برای اجرای الگوریتمها نداشته. این در حالی است که امروزه اگر بهعنوان مثال یک الگوریتم یادگیری عمیق با دسترسی به دادههای خوب اجرا شود، خروجی دریافت شده منجر به پیشرفتهای چشمگیری در یادگیری ماشین میشود.
انواع یادگیری ماشین
الگوریتمهای یادگیری ماشین بر سه نوع هستند:
یادگیری نظارت شده
یادگیری نظارت نشده
یادگیری تقویتی
یادگیری نظارت شده
اغلب روشهای یادگیری ماشین از یادگیری نظارت شده استفاده میکنند. در یادگیری ماشین نظارت شده، سیستم تلاش میکند تا از نمونههای پیشینی بیاموزد که در اختیار آن قرار گرفته. به عبارت دیگر، در این نوع یادگیری، سیستم تلاش میکند تا الگوها را بر اساس مثالهای داده شده به آن فرا بگیرد.
به بیان ریاضی، هنگامی که متغیر ورودی (X) و متغیر خروجی (Y) موجودند و میتوان بر اساس آنها از یک الگوریتم برای حصول یک تابع نگاشت ورودی به خروجی استفاده کرد در واقع یادگیری نظارت شده است. تابع نگاشت به صورت (Y = f(X نشان داده میشود.
مثال:
برای باز شدن مساله در ادامه توضیحات بیشتری ارائه میشود. همانطور که پیش از این بیان شد، در یادگیری ماشین مجموعه داده (هایی) به الگوریتم داده میشود و ماشین منطق خود را بر اساس آن مجموعه داده (ها) شکل میدهد. این مجموعه داده دارای سطرها و ستونهایی است. سطرها (که از آنها با عنوان رکورد و نمونه داده نیز یاد میشود) نماینده نمونه دادهها هستند. برای مثال اگر مجموعه داده مربوط به بازیهای فوتبال (وضعیت جوی) باشد، یک سطر حاوی اطلاعات یک بازی خاص است. ستونها (که از آنها با عنوان خصیصه، ویژگی، مشخصه نیز یاد میشود) در واقع ویژگیهایی هستند که هر نمونه داده را توصیف میکنند.https://beta.kaprila.com/a/templates_ver2/templates.php?ref=blog.faradars&id=string-1&w=760&h=140&t=string&bg=fffff3&hover=ffffcb&rows=3&cid=1871,391,2560&wr=cat_2_data_mining,cat_data_mining,cat_2_data_mining
در مثالی که پیشتر بیان شد، مواردی مانند وضعیت هوا شامل ابری بودن یا نبودن، آفتابی بودن یا نبودن، وجود یا عدم وجود مه، بارش یا عدم بارش باران و تاریخ بازی از جمله ویژگیهایی هستند که وضعیت یک مسابقه فوتبال را توصیف میکنند. حال اگر در این مجموعه داده به عنوان مثال، ستونی وجود داشته باشد که مشخص کند برای هر نمونه داده در شرایط جوی موجود برای آن نمونه خاص بازی فوتبال انجام شده یا نشده (برچسبها) اصطلاحا میگوییم مجموعه داده برچسبدار است. اگر آموزش الگوریتم از چنین مجموعه دادهای استفاده شود و به آن آموخته شود که بر اساس نمونه دادههایی که وضعیت آنها مشخص است (بازی فوتبال انجام شده یا نشده)، درباره نمونه دادههایی که وضعیت آنها نامشخص است تصمیمگیری کند، اصطلاحا گفته میشود یادگیری ماشین نظارت شده است.
مسائل یادگیری ماشین نظارت شده قابل تقسیم به دو دسته «دستهبندی» و «رگرسیون» هستند.
دستهبندی: یک مساله، هنگامی دستهبندی محسوب میشود که متغیر خروجی یک دسته یا گروه باشد. برای مثالی از این امر میتوان به تعلق یک نمونه به دستههای «سیاه» یا «سفید» و یک ایمیل به دستههای «هرزنامه» یا «غیر هرزنامه» اشاره کرد.
رگرسیون: یک مساله هنگامی رگرسیون است که متغیر خروجی یک مقدار حقیقی مانند «قد» باشد. در واقع در دستهبندی با متغیرهای گسسته و در رگرسیون با متغیرهای پیوسته کار میشود.
یادگیری نظارت نشده
در یادگیری نظارت نشده، الگوریتم باید خود به تنهایی بهدنبال ساختارهای جالب موجود در دادهها باشد. به بیان ریاضی، یادگیری نظارت نشده مربوط به زمانی است که در مجموعه داده فقط متغیرهای ورودی (X) وجود داشته باشند و هیچ متغیر داده خروجی موجود نباشد. به این نوع یادگیری، نظارت نشده گفته میشود زیرا برخلاف یادگیری نظارت شده، هیچ پاسخ صحیح داده شدهای وجود ندارد و ماشین خود باید به دنبال پاسخ باشد.
به بیان دیگر، هنگامی که الگوریتم برای کار کردن از مجموعه دادهای بهره گیرد که فاقد دادههای برچسبدار (متغیرهای خروجی) است، از مکانیزم دیگری برای یادگیری و تصمیمگیری استفاده میکند. به چنین نوع یادگیری، نظارت نشده گفته میشود. یادگیری نظارت نشده قابل تقسیم به مسائل خوشهبندی و انجمنی است.
قوانین انجمنی: یک مساله یادگیری هنگامی قوانین انجمنی محسوب میشود که هدف کشف کردن قواعدی باشد که بخش بزرگی از دادهها را توصیف میکنند. مثلا، «شخصی که کالای الف را خریداری کند، تمایل به خرید کالای ب نیز دارد».
خوشهبندی: یک مساله هنگامی خوشهبندی محسوب میشود که قصد کشف گروههای ذاتی (دادههایی که ذاتا در یک گروه خاص میگنجند) در دادهها وجود داشته باشد. مثلا، گروهبندی مشتریان بر اساس رفتار خرید آنها.
یادگیری تقویتی
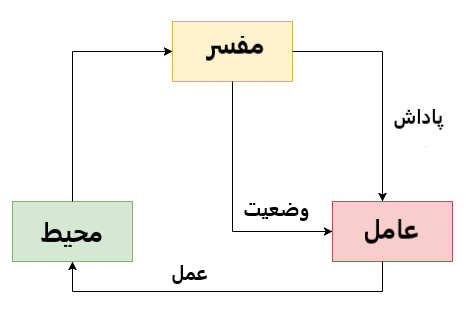
یک برنامه رایانهای که با محیط پویا در تعامل است باید به هدف خاصی دستیابد (مانند بازی کردن با یک رقیب یا راندن خودرو). این برنامه بازخوردهایی را با عنوان پاداشها و تنبیهها فراهم و فضای مساله خود را بر همین اساس هدایت میکند. با استفاده از یادگیری تقویتی، ماشین میآموزد که تصمیمات مشخصی را در محیطی که دائم در معرض آزمون و خطا است اتخاذ کند.
مثال:
ریاضیات هوشمندی
نظریه یادگیری ماشین، زمینهای است که در آن آمار و احتمال، علوم رایانه و مباحث الگوریتمی – بر مبنای یادگیری تکرار شونده – کاربرد دارد و میتواند برای ساخت نرمافزارهای کاربردی هوشمند مورد استفادده قرار بگیرد.
چرا نگرانی از ریاضیات؟
دلایل متعددی وجود دارد که آموختن ریاضیات برای یادگیری ماشین را الزامی میکند. برخی از این دلایل در ادامه آورده شدهاند.
انتخاب الگوریتم مناسب برای یک مساله خاص، که شامل در نظر گرفتن صحت، زمان آموزش، پیچیدگی مدل، تعداد پارامترها و تعداد مشخصهها است.
استفاده از موازنه واریانس-بایاس برای شناسایی حالاتی که بیشبرازش با کمبرازش در آنها به وقوع پیوسته است.
انتخاب تنظیمات پارامترها و استراتژیهای اعتبارسنجی.
تخمین دوره تصمیمگیری صحیح و عدم قطعیت.
چه سطحی از ریاضیات مورد نیاز است؟
پرسشی که برای اغلب افراد علاقمند به آموختن علم یادگیری ماشین مطرح است و بارها در مقالات و کنفرانسهای گوناگون این حوزه به آن پاسخ داده شده این است که چه میزان تسلط بر ریاضیات برای درک این علم مورد نیاز محسوب میشود. پاسخ این پرسش چند بُعدی و وابسته به سطح دانش ریاضی هر فرد و میزان علاقمندی آن شخص به یادگیری است. در ادامه حداقل دانش ریاضی که برای مهندسان یادگیری ماشین و تحلیلگران داده مورد نیاز است آورده شده.
جبر خطی: ماتریسها و عملیات روی آنها، پروجکشن، اتحاد و تجزیه، ماتریسهای متقارن، متعامدسازی.
نظریه آمار و احتمالات: قوانین احتمال و اصل (منطق)، نظریه بیزی، متغیرهای تصادفی، واریانس و امید ریاضی، توزیعهای توام و شرطی، توزیع استاندارد.
حساب: حساب دیفرانسیل و انتگرال، مشتقات جزئی.
الگوریتمها و بهینهسازی پیچیدگیها: درختهای دودویی، هیپ، استک

ارسال دیدگاه